## Flowchart: Data Processing Pipeline for LLM-Based Systems
### Overview
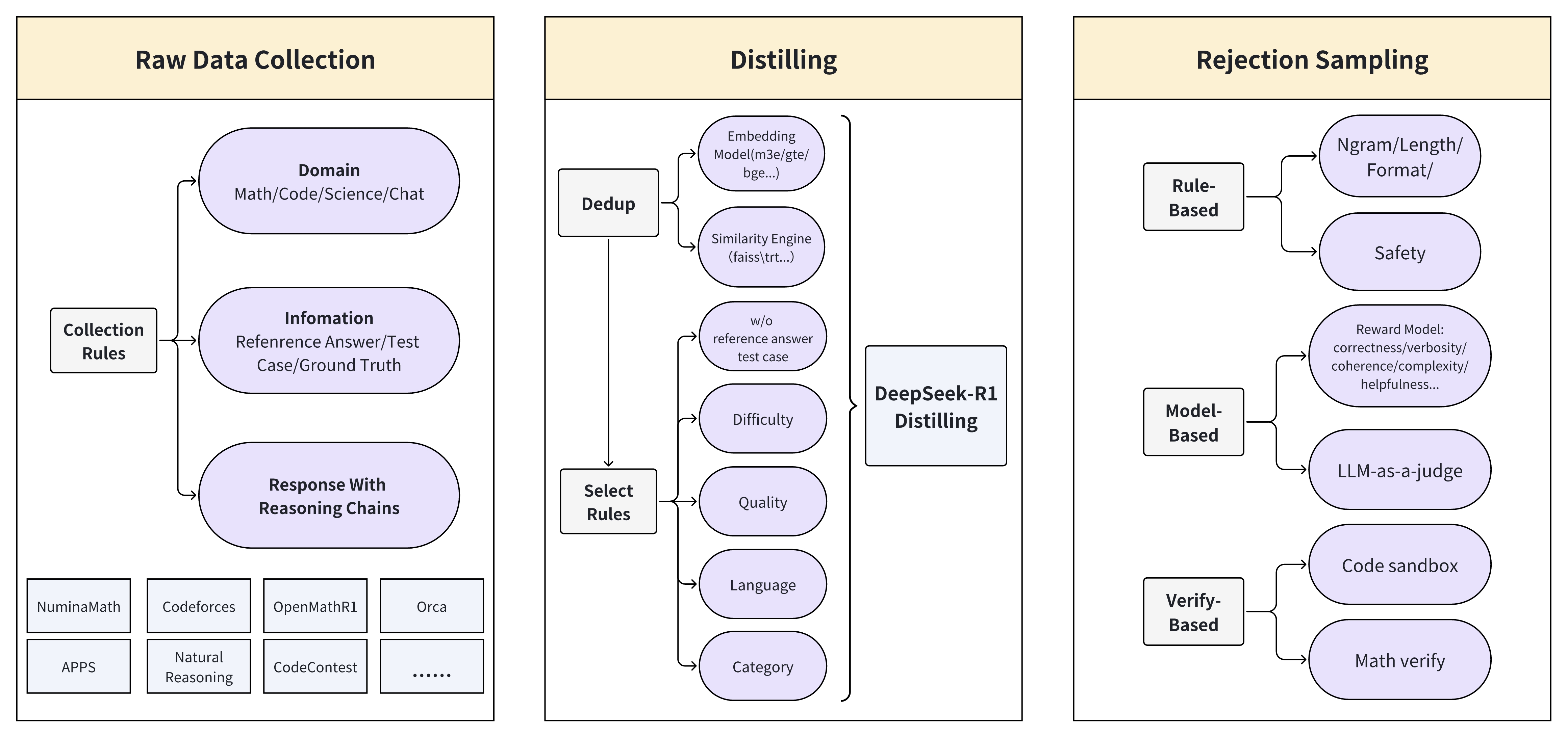
The flowchart illustrates a three-stage pipeline for processing data in LLM-based systems: **Raw Data Collection**, **Distilling**, and **Rejection Sampling**. Each stage includes specific components and rules for data handling, quality control, and filtering.
---
### Components/Axes
#### 1. Raw Data Collection
- **Domain**: Math, Code, Science, Chat
- **Collection Rules**:
- **Information**: Reference Answer, Test Case, Ground Truth
- **Response With Reasoning Chains**:
- Sources: NuminaMath, Codeforces, OpenMathR1, Orca, APPS, Natural Reasoning, CodeContest
#### 2. Distilling
- **Dedup**:
- Embedding Model (m3e/gte/bge...)
- Similarity Engine (faiss/tr...)
- w/o reference answer test case
- **DeepSeek-R1 Distilling**:
- Select Rules: Difficulty, Quality, Language, Category
#### 3. Rejection Sampling
- **Rule-Based**:
- Ngram/Length/Format
- Safety
- LLM-as-a-judge
- **Model-Based**:
- Reward Model: correctness/verbosity/coherence/complexity/helpfulness
- Verify-Based: Code sandbox, Math verify
---
### Detailed Analysis
#### Raw Data Collection
- **Domain**: Broad categorization of data sources (Math, Code, Science, Chat).
- **Information**: Focuses on structured data (Reference Answer, Test Case, Ground Truth).
- **Response With Reasoning Chains**: Aggregates outputs from diverse LLM benchmarks (e.g., NuminaMath for math, Codeforces for coding).
#### Distilling
- **Dedup**:
- Uses embeddings (e.g., m3e/gte/bge) and similarity engines (faiss/tr) to remove duplicates.
- Excludes test cases without reference answers.
- **DeepSeek-R1 Distilling**:
- Applies **Select Rules** to refine data based on difficulty, quality, language, and category.
#### Rejection Sampling
- **Rule-Based**:
- Filters data using syntactic rules (Ngram/Length/Format) and safety checks.
- Employs LLM-as-a-judge for qualitative assessment.
- **Model-Based**:
- Uses a **Reward Model** to evaluate data on correctness, verbosity, coherence, complexity, and helpfulness.
- Verifies code and math solutions via sandboxing and automated checks.
---
### Key Observations
1. **Data Flow**: Raw data is collected, distilled to remove redundancy and improve quality, then filtered using hybrid rule/model-based methods.
2. **Hybrid Approach**: Combines rule-based (e.g., safety checks) and model-based (e.g., reward model) rejection criteria.
3. **Domain-Specific Tools**: Tools like Codeforces and OpenMathR1 suggest domain-specific data collection.
4. **DeepSeek-R1 Integration**: Indicates a focus on iterative refinement using specialized distillation techniques.
---
### Interpretation
This pipeline emphasizes **quality assurance** at every stage:
- **Raw Data Collection** ensures diverse, domain-specific inputs.
- **Distilling** refines data by removing duplicates and applying domain-specific rules.
- **Rejection Sampling** acts as a final gatekeeper, using both rigid rules (e.g., format constraints) and nuanced model evaluations (e.g., helpfulness).
The use of **DeepSeek-R1** in the Distilling stage suggests an emphasis on iterative improvement, while the **Reward Model** in Rejection Sampling highlights a focus on multi-dimensional data quality metrics. The pipeline likely aims to balance efficiency (via rule-based filtering) and accuracy (via model-based evaluation) in LLM training or inference workflows.