## Data Processing Pipeline: Raw Data Collection, Distilling, and Rejection Sampling
### Overview
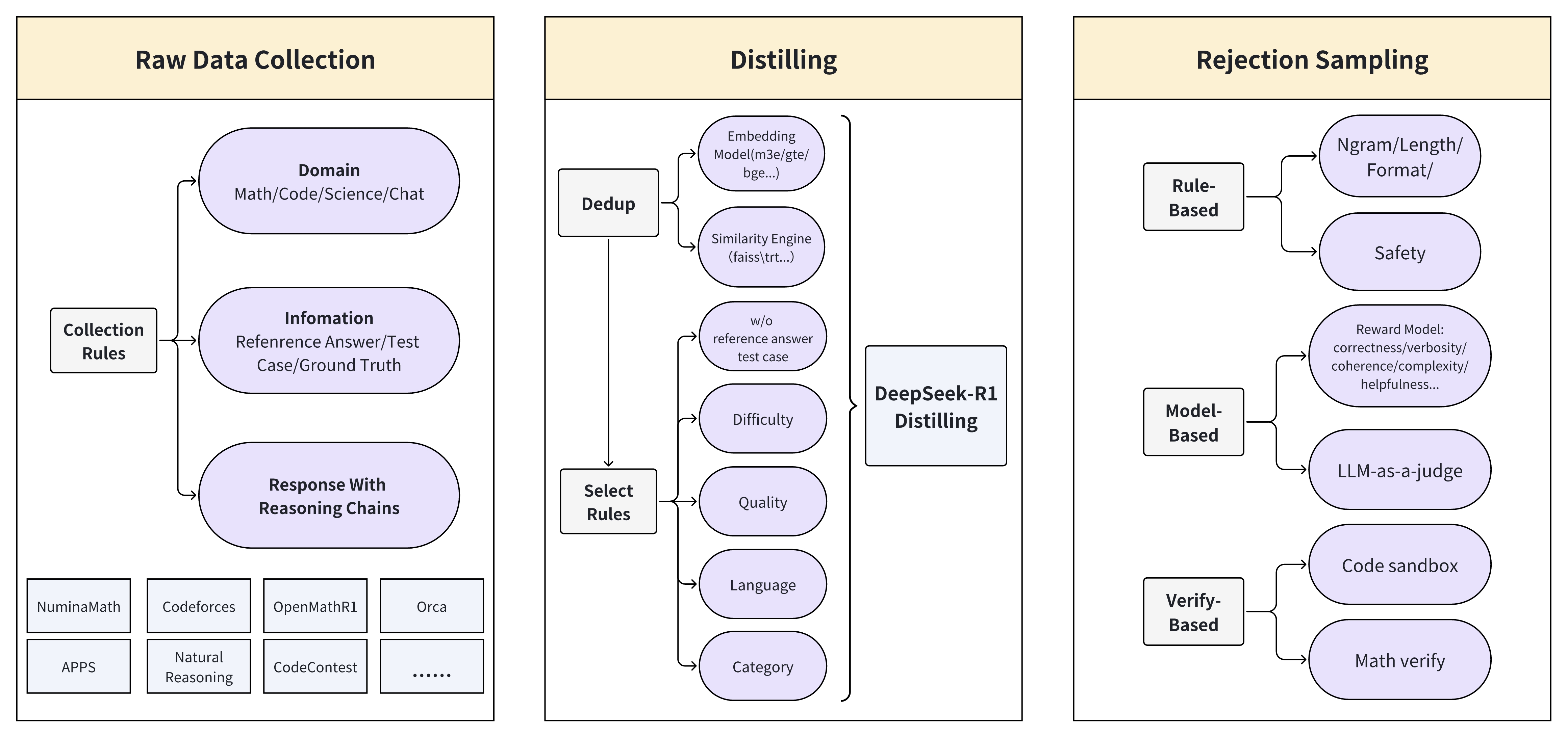
The image presents a diagram illustrating a data processing pipeline, divided into three main stages: Raw Data Collection, Distilling, and Rejection Sampling. Each stage involves specific processes and rules to refine and filter data.
### Components/Axes
**1. Raw Data Collection:**
* **Title:** Raw Data Collection (located at the top of the section)
* **Elements:**
* Collection Rules (rectangular box on the left)
* Domain (rounded rectangle): Math/Code/Science/Chat
* Infomation (rounded rectangle): Reference Answer/Test Case/Ground Truth
* Response With Reasoning Chains (rounded rectangle)
* APPS (rectangular box): Contains sub-elements: NuminaMath, Codeforces, OpenMathR1, Orca, Natural Reasoning, CodeContest, and "..." indicating more elements.
**2. Distilling:**
* **Title:** Distilling (located at the top of the section)
* **Elements:**
* Dedup (rectangular box on the left)
* Embedding Model (m3e/gte/bge...) (rounded rectangle)
* Similarity Engine (faiss\trt...) (rounded rectangle)
* w/o reference answer test case (rounded rectangle)
* Select Rules (rectangular box on the left)
* Difficulty (rounded rectangle)
* Quality (rounded rectangle)
* Language (rounded rectangle)
* Category (rounded rectangle)
* DeepSeek-R1 Distilling (rectangular box on the right)
**3. Rejection Sampling:**
* **Title:** Rejection Sampling (located at the top of the section)
* **Elements:**
* Rule-Based (rectangular box on the left)
* Ngram/Length/Format/ (rounded rectangle)
* Safety (rounded rectangle)
* Model-Based (rectangular box on the left)
* Reward Model: correctness/verbosity/coherence/complexity/helpfulness... (rounded rectangle)
* LLM-as-a-judge (rounded rectangle)
* Verify-Based (rectangular box on the left)
* Code sandbox (rounded rectangle)
* Math verify (rounded rectangle)
### Detailed Analysis or ### Content Details
**1. Raw Data Collection:**
* Collection Rules feeds into Domain, Infomation, and Response With Reasoning Chains.
* APPS lists specific applications or datasets used in the raw data collection.
**2. Distilling:**
* Dedup feeds into Embedding Model and Similarity Engine.
* Select Rules feeds into Difficulty, Quality, Language, and Category.
* All elements feed into DeepSeek-R1 Distilling.
**3. Rejection Sampling:**
* Rule-Based feeds into Ngram/Length/Format/ and Safety.
* Model-Based feeds into Reward Model and LLM-as-a-judge.
* Verify-Based feeds into Code sandbox and Math verify.
### Key Observations
* The diagram outlines a multi-stage process for data refinement.
* Each stage has specific rules and processes to filter and improve data quality.
* The flow of data is generally from left to right, with specific rules feeding into various data characteristics or models.
### Interpretation
The diagram illustrates a comprehensive data processing pipeline designed to collect, refine, and filter data for specific applications, likely related to machine learning or AI. The Raw Data Collection stage gathers data from various sources and domains. The Distilling stage focuses on refining the data by removing duplicates, assessing quality, and categorizing it. Finally, the Rejection Sampling stage uses rule-based, model-based, and verification-based methods to filter out undesirable data points, ensuring the final dataset is of high quality and suitable for its intended purpose. The pipeline emphasizes the importance of data quality and relevance in AI and machine learning applications.