\n
## Diagram: Data Pipeline for Model Training
### Overview
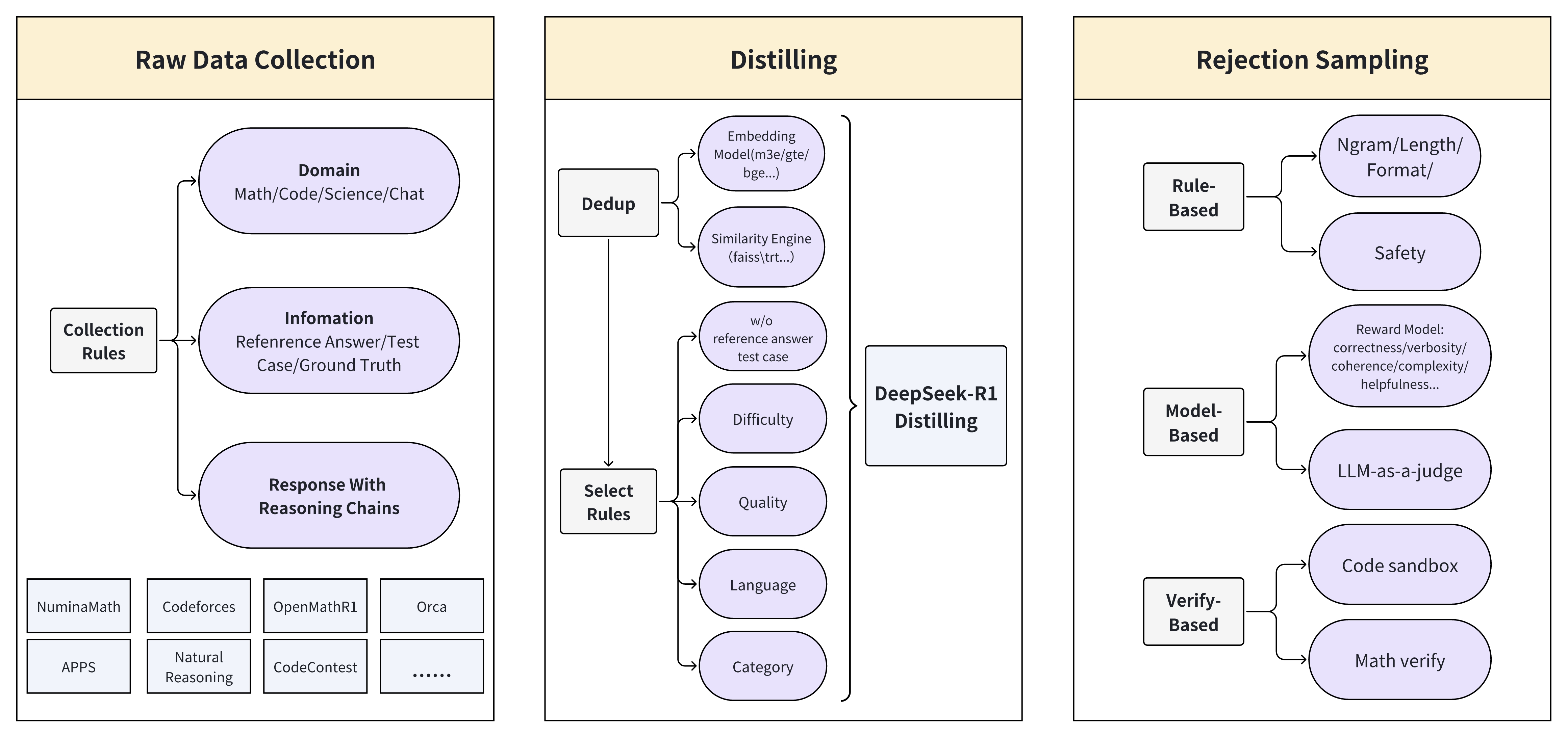
This diagram illustrates a data pipeline for training a model, encompassing raw data collection, distilling, and rejection sampling stages. The pipeline appears to be designed for generating high-quality training data, particularly for tasks involving math, code, science, and chat.
### Components/Axes
The diagram is structured into three main sections: "Raw Data Collection" (left), "Distilling" (center), and "Rejection Sampling" (right). Arrows indicate the flow of data between these stages. Within each section, several components are present, represented as boxes.
* **Raw Data Collection:**
* "Domain": Math/Code/Science/Chat
* "Collection Rules"
* "Information": Reference Answer/Test Case/Ground Truth
* "Response With Reasoning Chains"
* Datasets: "NumixMath", "Codeforces", "OpenMathR1", "Orca", "APPS", "Natural Reasoning", "CodeContest"
* **Distilling:**
* "Dedup": Input from "Raw Data Collection"
* "Similarity Engine": (faiss(trt...)) Input from "Dedup"
* "w/o reference answer test case" Input from "Similarity Engine"
* "DeepSeek-R1 Distilling" Input from "w/o reference answer test case", "Difficulty", "Quality", "Language", "Category"
* "Difficulty" Input from "Select Rules"
* "Quality" Input from "Select Rules"
* "Language" Input from "Select Rules"
* "Category" Input from "Select Rules"
* "Select Rules" Input from "Raw Data Collection"
* "Embedding Model(m3e/gte/bge...)" Input from "Dedup"
* **Rejection Sampling:**
* "Rule-Based": Input from "Distilling"
* "Model-Based": Input from "Distilling"
* "Verify-Based": Input from "Distilling"
* "Safety": Reward Model: correctness/verbosity/coherence/complexity/helpfulness...
* "LLM-as-a-judge"
* "Code sandbox"
* "Math verify"
* "Ngram/Length/Format/"
### Detailed Analysis
The data flow begins with "Raw Data Collection," where data from various sources (listed datasets) is gathered based on "Collection Rules" and "Information" (reference answers, test cases, ground truth). Responses with reasoning chains are also collected. This data is then fed into the "Distilling" stage.
Within "Distilling," the data undergoes deduplication ("Dedup") and similarity analysis using a "Similarity Engine" (faiss(trt...)). The "Dedup" process also utilizes an "Embedding Model" (m3e/gte/bge...). A key component is "DeepSeek-R1 Distilling," which receives input from the similarity engine and is influenced by factors like "Difficulty," "Quality," "Language," and "Category," which are selected by "Select Rules".
The output of "Distilling" is then passed to "Rejection Sampling," which employs three approaches: "Rule-Based," "Model-Based," and "Verify-Based." "Rule-Based" sampling incorporates a "Safety" component that evaluates data based on a "Reward Model" considering correctness, verbosity, coherence, complexity, and helpfulness. "Model-Based" sampling uses an "LLM-as-a-judge." "Verify-Based" sampling utilizes a "Code sandbox" and "Math verify." The "Rejection Sampling" stage also considers "Ngram/Length/Format/".
### Key Observations
The pipeline emphasizes data quality and relevance. The "Distilling" stage focuses on removing redundancy and selecting data based on specific criteria (difficulty, quality, language, category). The "Rejection Sampling" stage employs multiple methods to filter out undesirable data, ensuring the final training set is safe, accurate, and aligned with desired characteristics. The use of "faiss(trt...)" suggests a focus on efficient similarity search. The inclusion of "Code sandbox" and "Math verify" indicates a strong emphasis on correctness for code and mathematical tasks.
### Interpretation
This diagram represents a sophisticated data engineering pipeline designed to create a high-quality dataset for training large language models, particularly those focused on complex reasoning tasks like math and code. The pipeline's multi-stage approach—collection, distillation, and rejection sampling—reflects a commitment to data quality and safety. The use of multiple filtering mechanisms (rule-based, model-based, verify-based) suggests a robust approach to identifying and removing potentially harmful or inaccurate data. The pipeline is likely intended to address challenges associated with generating synthetic data or curating existing datasets for specialized applications. The emphasis on reasoning chains suggests the model is intended to not only provide answers but also explain its thought process. The pipeline is designed to create a dataset that is not only large but also carefully curated to maximize the performance and reliability of the resulting model.