## Bar Chart: Number of Tokens After First Step (k)
### Overview
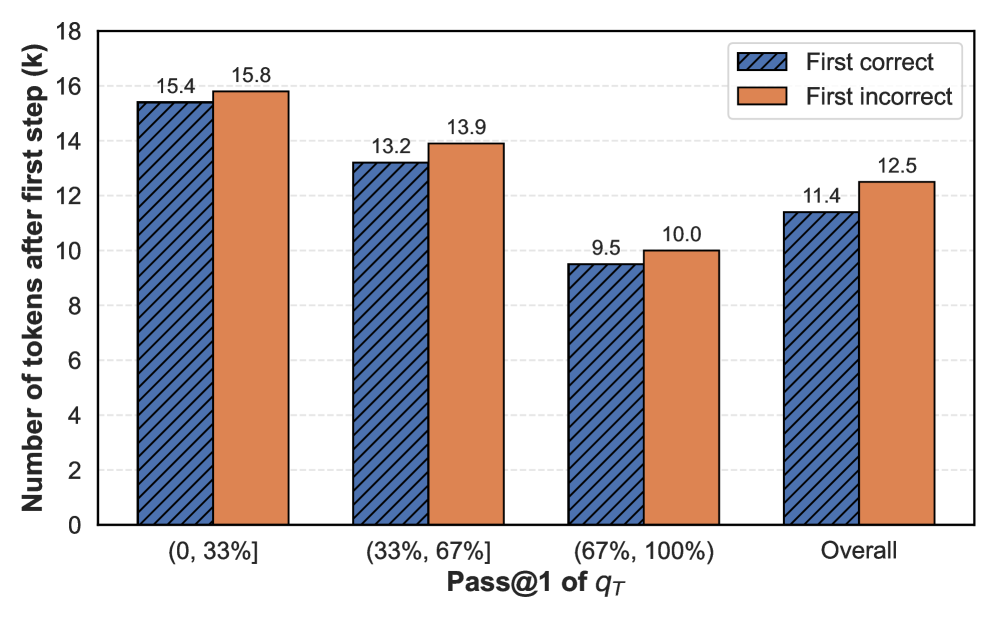
The chart compares the number of tokens remaining after the first step (k) across four categories of "Pass@1 of q_T" (0-33%, 33-67%, 67-100%, and Overall). Two data series are shown: "First correct" (blue striped bars) and "First incorrect" (orange bars). Values are labeled on top of each bar.
### Components/Axes
- **Y-axis**: "Number of tokens after first step (k)" (0–18, increments of 2)
- **X-axis**: Categories of "Pass@1 of q_T":
- (0, 33%]
- (33%, 67%]
- (67%, 100%)
- Overall
- **Legend**:
- Blue striped bars: "First correct"
- Orange bars: "First incorrect"
- **Placement**: Legend in top-right corner; bars grouped by x-axis categories.
### Detailed Analysis
1. **(0, 33%]**
- First correct: 15.4 tokens (blue)
- First incorrect: 15.8 tokens (orange)
2. **(33%, 67%]**
- First correct: 13.2 tokens (blue)
- First incorrect: 13.9 tokens (orange)
3. **(67%, 100%)**
- First correct: 9.5 tokens (blue)
- First incorrect: 10.0 tokens (orange)
4. **Overall**
- First correct: 11.4 tokens (blue)
- First incorrect: 12.5 tokens (orange)
### Key Observations
- **Highest values** occur in the (0, 33%] category for both data series.
- **Lowest values** occur in the (67%, 100%) category for both data series.
- "First incorrect" consistently exceeds "First correct" in all categories.
- The "Overall" category averages the previous three, showing a slight increase in tokens for "First incorrect" compared to individual categories.
### Interpretation
The data suggests that higher "Pass@1 of q_T" (success rate) correlates with fewer tokens remaining after the first step. However, the "Overall" category’s higher token count for "First incorrect" (12.5) compared to the (67%, 100%) category (10.0) may indicate an anomaly or averaging effect. The consistent gap between "First correct" and "First incorrect" implies that incorrect initial steps lead to more residual tokens, possibly due to additional processing or corrections. The chart highlights a trade-off between accuracy (Pass@1) and token efficiency in the first step.