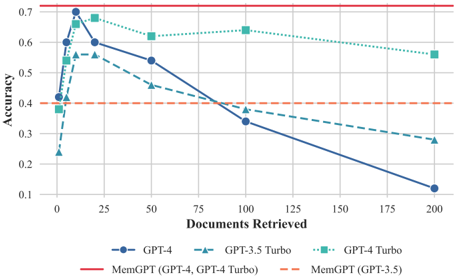
## Line Chart: Accuracy vs. Documents Retrieved
### Overview
This line chart illustrates the relationship between the number of documents retrieved and the accuracy achieved by different language models: GPT-4, GPT-3.5 Turbo, and GPT-4 Turbo. Two baseline accuracy levels, MemGPT (GPT-4, GPT-4 Turbo) and MemGPT (GPT-3.5) are also shown as horizontal lines. The chart demonstrates how accuracy changes as the number of retrieved documents increases for each model.
### Components/Axes
* **X-axis:** "Documents Retrieved" - Scale ranges from 0 to 200, with markers at 0, 25, 50, 75, 100, 125, 150, 175, and 200.
* **Y-axis:** "Accuracy" - Scale ranges from 0.1 to 0.7, with markers at 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, and 0.7.
* **Data Series:**
* GPT-4 (Blue line with circle markers)
* GPT-3.5 Turbo (Light Blue line with triangle markers)
* GPT-4 Turbo (Teal line with diamond markers)
* **Baseline Accuracy:**
* MemGPT (GPT-4, GPT-4 Turbo) (Red solid horizontal line)
* MemGPT (GPT-3.5) (Orange dashed horizontal line)
* **Legend:** Located at the bottom-center of the chart, clearly labeling each data series with its corresponding color and marker.
### Detailed Analysis
* **GPT-4 (Blue):** The line starts at approximately 0 documents retrieved with an accuracy of 0.7. It then decreases steadily as the number of documents retrieved increases.
* 0 Documents: ~0.7 Accuracy
* 25 Documents: ~0.62 Accuracy
* 50 Documents: ~0.52 Accuracy
* 75 Documents: ~0.45 Accuracy
* 100 Documents: ~0.38 Accuracy
* 125 Documents: ~0.32 Accuracy
* 150 Documents: ~0.27 Accuracy
* 175 Documents: ~0.22 Accuracy
* 200 Documents: ~0.16 Accuracy
* **GPT-3.5 Turbo (Light Blue):** The line begins at approximately 0 documents retrieved with an accuracy of 0.38. It initially rises sharply to around 0.68 at 25 documents, then declines more gradually.
* 0 Documents: ~0.38 Accuracy
* 25 Documents: ~0.68 Accuracy
* 50 Documents: ~0.55 Accuracy
* 75 Documents: ~0.48 Accuracy
* 100 Documents: ~0.41 Accuracy
* 125 Documents: ~0.36 Accuracy
* 150 Documents: ~0.32 Accuracy
* 175 Documents: ~0.29 Accuracy
* 200 Documents: ~0.27 Accuracy
* **GPT-4 Turbo (Teal):** The line starts at approximately 0 documents retrieved with an accuracy of 0.65. It decreases at a slower rate than GPT-4, remaining above GPT-4 for most of the range.
* 0 Documents: ~0.65 Accuracy
* 25 Documents: ~0.67 Accuracy
* 50 Documents: ~0.61 Accuracy
* 75 Documents: ~0.57 Accuracy
* 100 Documents: ~0.52 Accuracy
* 125 Documents: ~0.49 Accuracy
* 150 Documents: ~0.46 Accuracy
* 175 Documents: ~0.43 Accuracy
* 200 Documents: ~0.41 Accuracy
* **MemGPT (GPT-4, GPT-4 Turbo) (Red):** A horizontal line at approximately 0.72 Accuracy.
* **MemGPT (GPT-3.5) (Orange):** A horizontal line at approximately 0.4 Accuracy.
### Key Observations
* GPT-4 exhibits the steepest decline in accuracy as the number of retrieved documents increases.
* GPT-3.5 Turbo shows an initial increase in accuracy with a small number of retrieved documents, then a gradual decline.
* GPT-4 Turbo maintains a relatively stable accuracy compared to the other models, though it still decreases with more documents.
* GPT-4 starts with the highest accuracy, but quickly falls below the MemGPT (GPT-4, GPT-4 Turbo) baseline.
* GPT-3.5 Turbo starts below the MemGPT (GPT-3.5) baseline, but briefly exceeds it.
### Interpretation
The chart suggests that increasing the number of retrieved documents does not necessarily improve accuracy for these language models. In fact, for GPT-4, it significantly *decreases* accuracy. This could be due to the models being overwhelmed by irrelevant information or struggling to synthesize information from a larger corpus. The MemGPT baselines represent a level of accuracy achievable with a more focused approach, potentially using memory or retrieval mechanisms to prioritize relevant information. The initial accuracy boost for GPT-3.5 Turbo might indicate that a small amount of context is beneficial, but beyond a certain point, the benefits diminish. The relatively stable performance of GPT-4 Turbo suggests it may be more robust to the inclusion of additional documents, potentially due to architectural differences or training data. The chart highlights the trade-off between recall (retrieving more documents) and precision (maintaining accuracy) in information retrieval systems. The models are all performing worse than the MemGPT baselines as the number of documents increases, suggesting that the retrieval strategy used for the chart is not optimal for these models.