TECHNICAL ASSET FINGERPRINT
b2117a0be0bc145e55106b3b
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
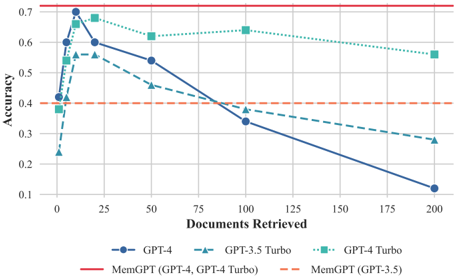
## Line Chart: Accuracy vs. Documents Retrieved for GPT Models and MemGPT Variants
### Overview
The image displays a line chart comparing the accuracy of different language models and configurations as the number of retrieved documents increases. The chart plots "Accuracy" on the vertical axis against "Documents Retrieved" on the horizontal axis. It includes three GPT model series and two horizontal reference lines representing MemGPT configurations.
### Components/Axes
* **Chart Type:** Multi-series line chart with markers.
* **X-Axis:** Label: "Documents Retrieved". Scale: Linear, from 0 to 200, with major tick marks at 0, 25, 50, 75, 100, 125, 150, 175, 200.
* **Y-Axis:** Label: "Accuracy". Scale: Linear, from 0.1 to 0.7, with major tick marks at 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7.
* **Legend:** Positioned at the bottom center of the chart. Contains five entries:
1. `GPT-4`: Solid dark blue line with circle markers.
2. `GPT-3.5 Turbo`: Dashed teal line with upward-pointing triangle markers.
3. `GPT-4 Turbo`: Dotted green line with square markers.
4. `MemGPT (GPT-4, GPT-4 Turbo)`: Solid red horizontal line.
5. `MemGPT (GPT-3.5)`: Dashed orange horizontal line.
* **Grid:** Light gray gridlines are present for both axes.
### Detailed Analysis
**Data Series Trends and Approximate Points:**
1. **GPT-4 (Solid Blue Line, Circle Markers):**
* **Trend:** Sharp initial increase to a peak, followed by a steady, significant decline as more documents are retrieved.
* **Data Points (Approximate):**
* At ~1 document: Accuracy ~0.40
* At ~5 documents: Accuracy ~0.60
* At ~10 documents: **Peak Accuracy ~0.68**
* At ~20 documents: Accuracy ~0.60
* At ~50 documents: Accuracy ~0.55
* At ~100 documents: Accuracy ~0.33
* At ~200 documents: Accuracy ~0.12
2. **GPT-3.5 Turbo (Dashed Teal Line, Triangle Markers):**
* **Trend:** Sharp initial increase to a peak, followed by a steady decline. The decline is less steep than GPT-4's after the peak but continues downward.
* **Data Points (Approximate):**
* At ~1 document: Accuracy ~0.24
* At ~5 documents: Accuracy ~0.40
* At ~10 documents: Accuracy ~0.56
* At ~20 documents: **Peak Accuracy ~0.57**
* At ~50 documents: Accuracy ~0.47
* At ~100 documents: Accuracy ~0.37
* At ~200 documents: Accuracy ~0.28
3. **GPT-4 Turbo (Dotted Green Line, Square Markers):**
* **Trend:** Sharp initial increase to a peak, followed by a very gradual, shallow decline. It maintains the highest accuracy among the non-MemGPT models for larger document counts.
* **Data Points (Approximate):**
* At ~1 document: Accuracy ~0.37
* At ~5 documents: Accuracy ~0.62
* At ~10 documents: **Peak Accuracy ~0.67**
* At ~20 documents: Accuracy ~0.66
* At ~50 documents: Accuracy ~0.62
* At ~100 documents: Accuracy ~0.64
* At ~200 documents: Accuracy ~0.57
4. **MemGPT (GPT-4, GPT-4 Turbo) (Solid Red Horizontal Line):**
* **Trend:** Constant accuracy, independent of the number of documents retrieved.
* **Value:** Accuracy = 0.70 (constant).
5. **MemGPT (GPT-3.5) (Dashed Orange Horizontal Line):**
* **Trend:** Constant accuracy, independent of the number of documents retrieved.
* **Value:** Accuracy = 0.40 (constant).
### Key Observations
1. **Performance Peak:** All three standard GPT models (GPT-4, GPT-3.5 Turbo, GPT-4 Turbo) exhibit a "sweet spot" for accuracy when retrieving a small number of documents (between ~5 and ~20). Accuracy degrades as more documents are added beyond this point.
2. **Model Comparison at Peak:** At their respective peaks, GPT-4 (~0.68) and GPT-4 Turbo (~0.67) achieve very similar maximum accuracy, both significantly higher than GPT-3.5 Turbo's peak (~0.57).
3. **Degradation Rate:** The rate of accuracy decline with more documents varies: GPT-4 degrades the most severely, GPT-3.5 Turbo degrades moderately, and GPT-4 Turbo degrades the least, showing more robustness.
4. **MemGPT Baselines:** The MemGPT configurations provide constant accuracy benchmarks. The MemGPT (GPT-4, GPT-4 Turbo) line at 0.70 sits above the peak of any standard model, suggesting a performance ceiling or target. The MemGPT (GPT-3.5) line at 0.40 is below the peak of all models but is eventually surpassed by GPT-3.5 Turbo and GPT-4 Turbo as their accuracy falls.
5. **Crossover Points:** GPT-4 Turbo's accuracy line crosses above GPT-4's line after approximately 20 documents and remains higher. GPT-3.5 Turbo's line crosses above GPT-4's line after approximately 75 documents.
### Interpretation
This chart illustrates a critical challenge in retrieval-augmented generation (RAG) systems: **more retrieved context does not guarantee better performance** and can, in fact, be detrimental.
* **The "Less is More" Effect:** The initial sharp rise suggests models benefit from relevant retrieved information. However, the subsequent decline indicates that adding more documents introduces noise, distracts the model, or exceeds its effective context window processing capability, leading to accuracy loss. This is a classic signal of the "lost in the middle" phenomenon or context dilution.
* **Model Robustness:** GPT-4 Turbo demonstrates superior robustness to increasing context size compared to GPT-4 and GPT-3.5 Turbo, maintaining higher accuracy for longer. This could be due to architectural improvements or better attention mechanisms for handling long contexts.
* **MemGPT as a Benchmark:** The flat MemGPT lines likely represent the performance of a system designed to manage its own memory dynamically, decoupling performance from the raw number of documents retrieved. The fact that the GPT-4-based MemGPT line (0.70) is above all standard model peaks suggests that intelligent memory management can outperform simple retrieval scaling. The chart argues for the value of systems like MemGPT that curate and manage information rather than just retrieving more of it.
* **Practical Implication:** For engineers building RAG systems, this data strongly suggests implementing a **retrieval tuning mechanism**. There is an optimal number of documents to retrieve (around 10-20 for these models), and systems should be designed to find this optimum or use a memory-augmented approach to avoid the performance degradation seen with large retrieval sets.
DECODING INTELLIGENCE...