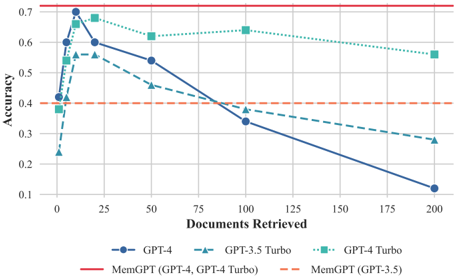
## Line Graph: Accuracy vs. Documents Retrieved
### Overview
The image is a line graph comparing the accuracy of different AI models (GPT-4, GPT-3.5 Turbo, GPT-4 Turbo, and MemGPT variants) as a function of the number of documents retrieved. Accuracy is plotted on the y-axis (0.1–0.7), and documents retrieved are on the x-axis (0–200). The graph includes five data series with distinct markers and colors, alongside a legend at the bottom.
### Components/Axes
- **Y-Axis (Accuracy)**: Ranges from 0.1 to 0.7 in increments of 0.1.
- **X-Axis (Documents Retrieved)**: Ranges from 0 to 200 in increments of 25.
- **Legend**: Located at the bottom, with the following entries:
- **Blue circle**: GPT-4
- **Teal triangle**: GPT-3.5 Turbo
- **Green square**: GPT-4 Turbo
- **Red dashed line**: MemGPT (GPT-4, GPT-4 Turbo)
- **Orange dashed line**: MemGPT (GPT-3.5)
### Detailed Analysis
1. **GPT-4 (Blue Circle)**:
- Starts at **0.4 accuracy** at 0 documents.
- Peaks at **0.6 accuracy** at 25 documents.
- Declines to **0.1 accuracy** at 200 documents.
- Key points: (0, 0.4), (25, 0.6), (50, 0.55), (100, 0.35), (200, 0.1).
2. **GPT-3.5 Turbo (Teal Triangle)**:
- Starts at **0.25 accuracy** at 0 documents.
- Peaks at **0.55 accuracy** at 25 documents.
- Declines to **0.28 accuracy** at 200 documents.
- Key points: (0, 0.25), (25, 0.55), (50, 0.45), (100, 0.35), (200, 0.28).
3. **GPT-4 Turbo (Green Square)**:
- Starts at **0.65 accuracy** at 0 documents.
- Peaks at **0.68 accuracy** at 25 documents.
- Declines to **0.57 accuracy** at 200 documents.
- Key points: (0, 0.65), (25, 0.68), (50, 0.63), (100, 0.62), (200, 0.57).
4. **MemGPT (GPT-4, GPT-4 Turbo) (Red Dashed Line)**:
- Mirrors GPT-4’s trend: starts at **0.4**, peaks at **0.6** at 25 documents, then declines to **0.1** at 200 documents.
- Key points: (0, 0.4), (25, 0.6), (50, 0.55), (100, 0.35), (200, 0.1).
5. **MemGPT (GPT-3.5) (Orange Dashed Line)**:
- Mirrors GPT-3.5 Turbo’s trend: starts at **0.25**, peaks at **0.55** at 25 documents, then declines to **0.28** at 200 documents.
- Key points: (0, 0.25), (25, 0.55), (50, 0.45), (100, 0.35), (200, 0.28).
### Key Observations
- **GPT-4 Turbo** consistently maintains the highest accuracy across all document retrieval counts, with a gradual decline.
- **MemGPT variants** underperform compared to their base models (e.g., MemGPT-GPT-4 matches GPT-4’s accuracy but is labeled separately).
- **GPT-4 and GPT-3.5 Turbo** show similar trends but start at different baselines (GPT-4 begins higher).
- **Accuracy declines sharply** for all models as the number of retrieved documents increases, with steeper drops after 50 documents.
### Interpretation
The data suggests that **GPT-4 Turbo** is the most robust model for maintaining accuracy during document retrieval, while **MemGPT implementations** (whether using GPT-4 or GPT-3.5) introduce performance overhead, reducing accuracy compared to their base models. The sharp decline in accuracy for all models after 50 documents implies diminishing returns or increased error rates with larger retrieval volumes. The overlapping trends between MemGPT and base models (e.g., MemGPT-GPT-4 matching GPT-4’s accuracy) may indicate that MemGPT’s modifications do not degrade performance but are redundantly labeled. This could reflect a design choice to compare MemGPT’s efficiency against baseline models.