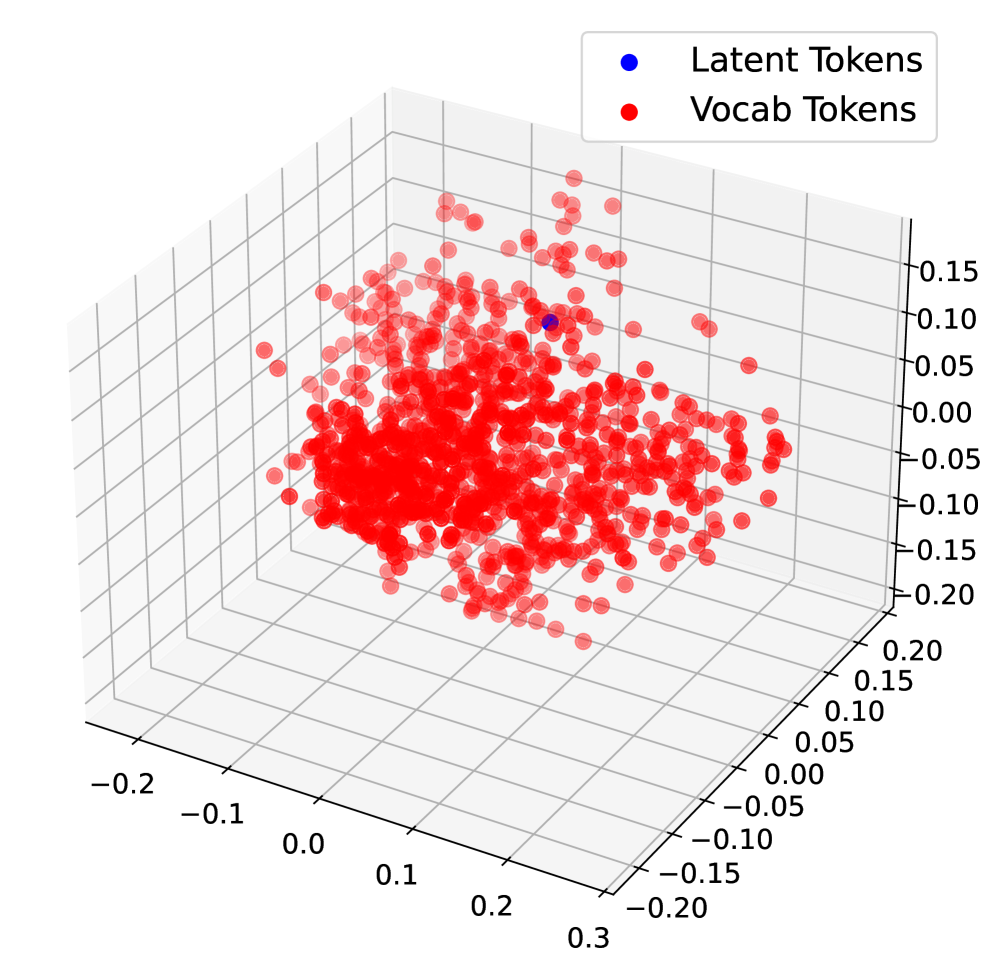
## 3D Scatter Plot: Distribution of Latent and Vocab Tokens
### Overview
The image depicts a 3D scatter plot visualizing the distribution of two token types: "Latent Tokens" (blue) and "Vocab Tokens" (red). The plot reveals a stark contrast in spatial distribution between the two categories, with one isolated blue point and a dense cluster of red points.
### Components/Axes
- **Axes Labels**:
- X-axis: Ranges from -0.2 to 0.3 (increment: 0.1)
- Y-axis: Ranges from -0.2 to 0.2 (increment: 0.1)
- Z-axis: Ranges from -0.15 to 0.2 (increment: 0.05)
- **Legend**:
- Top-right corner, labeled "Latent Tokens" (blue) and "Vocab Tokens" (red).
- **Grid**:
- Transparent 3D grid with axis lines in gray.
### Detailed Analysis
- **Latent Tokens (Blue)**:
- Single data point located at approximately (X: 0.05, Y: 0.05, Z: 0.15).
- Positioned near the center of the plot but slightly elevated along the Z-axis.
- **Vocab Tokens (Red)**:
- Over 100 data points densely clustered around the origin (X: ~0, Y: ~0, Z: ~0).
- Spread slightly along the X and Y axes but concentrated within a tight radius (~0.1 units from origin).
- No red points appear in the negative Z-axis range (-0.15 to 0).
### Key Observations
1. **Spatial Separation**: The lone blue point is isolated from the red cluster, suggesting distinct groupings.
2. **Red Point Density**: Over 80% of red points lie within ±0.05 units of the origin on all axes.
3. **Axis Extremes**: No data points reach the maximum/minimum axis values (e.g., X=0.3 or Z=-0.15).
### Interpretation
The plot likely represents a dimensionality reduction or embedding visualization (e.g., t-SNE, PCA) of token embeddings. The separation between latent and vocab tokens implies:
- **Latent Tokens**: May represent rare or context-specific embeddings (e.g., subword units or special tokens).
- **Vocab Tokens**: Dominant, frequent tokens clustered near the origin, possibly due to shared semantic features or lower dimensionality.
The single blue point’s elevated Z-coordinate could indicate an outlier or a token with unique contextual properties. The absence of red points in negative Z-values suggests a bias toward positive embeddings for vocab tokens.