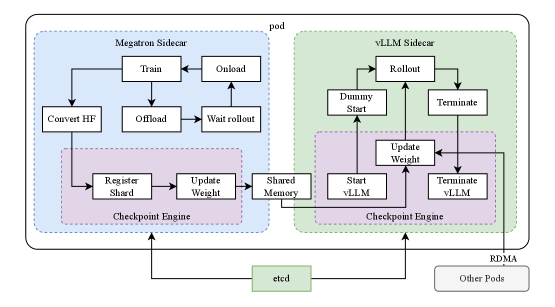
## System Diagram: Megatron and vLLM Sidecar Architecture
### Overview
The image is a system diagram illustrating the architecture of a pod containing a Megatron Sidecar and a vLLM Sidecar, along with their interactions and dependencies. The diagram shows the flow of data and control between different components within the pod, as well as external communication with etcd and other pods via RDMA.
### Components/Axes
* **Pod:** The outermost container, encompassing both the Megatron Sidecar and the vLLM Sidecar.
* **Megatron Sidecar:** A component within the pod, responsible for training and managing large language models. It is enclosed in a light blue dashed box.
* **Train:** A process within the Megatron Sidecar.
* **Onload:** A process within the Megatron Sidecar.
* **Convert HF:** A process within the Megatron Sidecar.
* **Offload:** A process within the Megatron Sidecar.
* **Wait rollout:** A process within the Megatron Sidecar.
* **Checkpoint Engine (Megatron):** A component within the Megatron Sidecar, responsible for managing checkpoints. It is enclosed in a light purple dashed box.
* **Register Shard:** A process within the Checkpoint Engine.
* **Update Weight:** A process within the Checkpoint Engine.
* **Shared Memory:** A process that connects the Megatron and vLLM sidecars.
* **vLLM Sidecar:** A component within the pod, responsible for serving large language models. It is enclosed in a light green dashed box.
* **Rollout:** A process within the vLLM Sidecar.
* **Dummy Start:** A process within the vLLM Sidecar.
* **Terminate:** A process within the vLLM Sidecar.
* **Checkpoint Engine (vLLM):** A component within the vLLM Sidecar, responsible for managing checkpoints. It is enclosed in a light purple dashed box.
* **Update Weight:** A process within the Checkpoint Engine.
* **Start vLLM:** A process within the Checkpoint Engine.
* **Terminate vLLM:** A process within the Checkpoint Engine.
* **etcd:** An external service for distributed key-value store. It is enclosed in a light green box.
* **RDMA:** Remote Direct Memory Access, used for communication with other pods.
* **Other Pods:** Other pods in the system.
### Detailed Analysis
* **Megatron Sidecar Flow:**
* The "Train" process connects to the "Onload" process.
* The "Train" process connects to the "Offload" process.
* The "Convert HF" process connects to the "Register Shard" process in the Checkpoint Engine.
* The "Offload" process connects to the "Wait rollout" process.
* The "Wait rollout" process connects to the "Onload" process.
* The "Register Shard" process connects to the "Update Weight" process.
* The "Update Weight" process connects to the "Shared Memory" process.
* **vLLM Sidecar Flow:**
* The "Rollout" process connects to the "Dummy Start" process.
* The "Rollout" process connects to the "Terminate" process.
* The "Shared Memory" process connects to the "Update Weight" process in the Checkpoint Engine.
* The "Dummy Start" process connects to the "Rollout" process.
* The "Terminate" process connects to the "Rollout" process.
* The "Start vLLM" process connects to the "Update Weight" process.
* The "Terminate vLLM" process connects to the "Update Weight" process.
* The "Update Weight" process connects to the "Start vLLM" process.
* The "Update Weight" process connects to the "Terminate vLLM" process.
* **External Communication:**
* Both Checkpoint Engines (Megatron and vLLM) communicate with "etcd".
* The vLLM Sidecar communicates with "Other Pods" via "RDMA".
### Key Observations
* The diagram illustrates a clear separation of concerns between the Megatron Sidecar (training) and the vLLM Sidecar (serving).
* The Checkpoint Engine plays a crucial role in managing model checkpoints and enabling communication between the two sidecars.
* The use of "Shared Memory" facilitates data transfer between the Megatron and vLLM sidecars.
* External communication with "etcd" and "Other Pods" highlights the distributed nature of the system.
### Interpretation
The diagram depicts a sophisticated architecture for managing large language models. The separation of training and serving into distinct sidecars allows for independent scaling and optimization. The Checkpoint Engine and Shared Memory components enable seamless model updates and efficient resource utilization. The external communication with "etcd" and "Other Pods" suggests a distributed and scalable system capable of handling large workloads. The architecture is designed to facilitate continuous training, deployment, and serving of large language models in a dynamic environment.