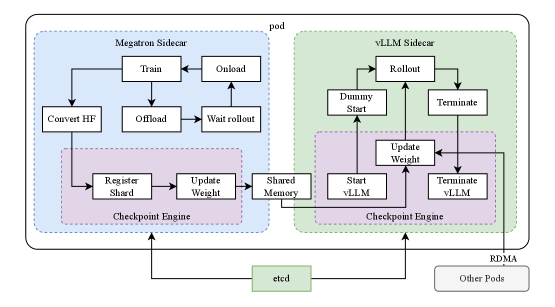
## Diagram: System Architecture for Model Training and Deployment
### Overview
The image depicts a system architecture diagram illustrating the interaction between two sidecars – Megatron and vLLM – within a pod, utilizing shared memory and a checkpoint engine. The diagram outlines the process of model training (Megatron) and subsequent rollout/deployment (vLLM). The system also interacts with `etcd` and other pods via RDMA.
### Components/Axes
The diagram consists of the following components:
* **Megatron Sidecar:** Represented by a light blue box.
* **vLLM Sidecar:** Represented by a light green box.
* **Checkpoint Engine:** Represented by a purple box, present in both sidecars.
* **Shared Memory:** A central block connecting the two sidecars.
* **etcd:** A key-value store, positioned at the bottom center.
* **Other Pods:** Represented by a gray box, positioned at the bottom right.
* **RDMA:** Indicates Remote Direct Memory Access, connecting "Other Pods" to the vLLM sidecar.
* **Pod:** A dashed gray rectangle encompassing both sidecars.
The diagram uses arrows to indicate the flow of data and control between these components. The following processes are depicted:
* **Megatron Sidecar Processes:** Convert HF, Train, Onload, Offload, Wait Rollout, Register Shard, Update Weight.
* **vLLM Sidecar Processes:** Rollout, Dummy Start, Update Weight, Start vLLM, Terminate vLLM, Terminate.
### Detailed Analysis / Content Details
The diagram illustrates a workflow as follows:
1. **Megatron Sidecar:**
* The process begins with "Convert HF".
* "Train" initiates the model training process.
* "Onload" and "Offload" represent data transfer operations.
* "Wait Rollout" waits for the vLLM sidecar to be ready.
* The "Checkpoint Engine" within the Megatron sidecar handles "Register Shard" and "Update Weight".
2. **Shared Memory:**
* Data is transferred between the Megatron and vLLM sidecars via "Shared Memory".
3. **vLLM Sidecar:**
* "Rollout" initiates the deployment process.
* "Dummy Start" is a placeholder or initialization step.
* "Update Weight" updates the model weights.
* "Start vLLM" starts the vLLM service.
* "Terminate vLLM" terminates the vLLM service.
* The "Checkpoint Engine" within the vLLM sidecar is involved in updating weights and managing the vLLM lifecycle.
4. **External Interactions:**
* The "Checkpoint Engine" in both sidecars interacts with `etcd`.
* "Other Pods" communicate with the vLLM sidecar via RDMA.
### Key Observations
* The diagram highlights a clear separation of concerns between model training (Megatron) and model deployment (vLLM).
* The use of "Shared Memory" suggests a high-performance data exchange mechanism.
* The "Checkpoint Engine" plays a crucial role in both training and deployment, likely managing model versions and updates.
* The interaction with `etcd` indicates a distributed coordination system.
* RDMA is used for efficient communication with other pods.
### Interpretation
This diagram represents a sophisticated system for training and deploying large language models. The architecture leverages sidecars to isolate the training and deployment processes, promoting modularity and scalability. The use of shared memory suggests an attempt to minimize data transfer overhead, crucial for large models. The checkpoint engine and `etcd` integration provide robust model management and coordination capabilities. The RDMA connection to other pods indicates a distributed deployment strategy.
The diagram suggests a workflow where the Megatron sidecar trains the model, periodically updating weights in shared memory. The vLLM sidecar then rolls out the updated model, utilizing the shared weights for inference. The `etcd` store likely maintains metadata about the model versions and their availability. The overall design emphasizes efficiency, scalability, and reliability in the context of large language model serving. The "Dummy Start" process in the vLLM sidecar is a curious element, potentially representing a pre-initialization step or a placeholder for future functionality.