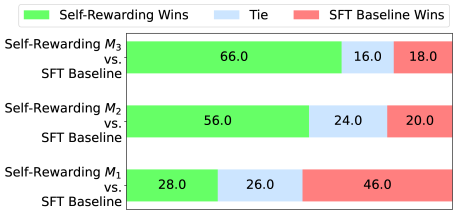
## Stacked Bar Chart: Self-Rewarding vs. SFT Baseline Wins
### Overview
The image is a stacked bar chart comparing the performance of Self-Rewarding models (M1, M2, M3) against an SFT Baseline. The chart shows the percentage of wins, ties, and SFT Baseline wins for each comparison. Each horizontal bar represents a comparison between a Self-Rewarding model and the SFT Baseline. The bars are segmented to show the percentage of wins for each category.
### Components/Axes
* **Y-axis Labels:**
* Self-Rewarding M3 vs. SFT Baseline
* Self-Rewarding M2 vs. SFT Baseline
* Self-Rewarding M1 vs. SFT Baseline
* **X-axis:** Implicitly represents the percentage of outcomes (Wins, Ties, SFT Baseline Wins). The values are displayed directly on the bars.
* **Legend (Top):**
* Green: Self-Rewarding Wins
* Light Blue: Tie
* Light Red: SFT Baseline Wins
### Detailed Analysis
The chart presents three comparisons, each represented by a stacked bar.
* **Self-Rewarding M3 vs. SFT Baseline:**
* Self-Rewarding Wins: 66.0% (Green)
* Tie: 16.0% (Light Blue)
* SFT Baseline Wins: 18.0% (Light Red)
* **Self-Rewarding M2 vs. SFT Baseline:**
* Self-Rewarding Wins: 56.0% (Green)
* Tie: 24.0% (Light Blue)
* SFT Baseline Wins: 20.0% (Light Red)
* **Self-Rewarding M1 vs. SFT Baseline:**
* Self-Rewarding Wins: 28.0% (Green)
* Tie: 26.0% (Light Blue)
* SFT Baseline Wins: 46.0% (Light Red)
### Key Observations
* Self-Rewarding M3 has the highest percentage of Self-Rewarding Wins (66.0%).
* Self-Rewarding M1 has the lowest percentage of Self-Rewarding Wins (28.0%) and the highest percentage of SFT Baseline Wins (46.0%).
* The percentage of ties varies between 16.0% and 26.0%.
### Interpretation
The chart demonstrates the relative performance of three Self-Rewarding models (M1, M2, and M3) compared to an SFT Baseline. Self-Rewarding M3 appears to be the most effective, with the highest win rate against the SFT Baseline. Self-Rewarding M1, on the other hand, performs the worst, with the SFT Baseline winning a significant portion of the time. The tie percentages are relatively consistent across all three comparisons. The data suggests that the Self-Rewarding approach can be effective, but its performance is highly dependent on the specific model implementation.