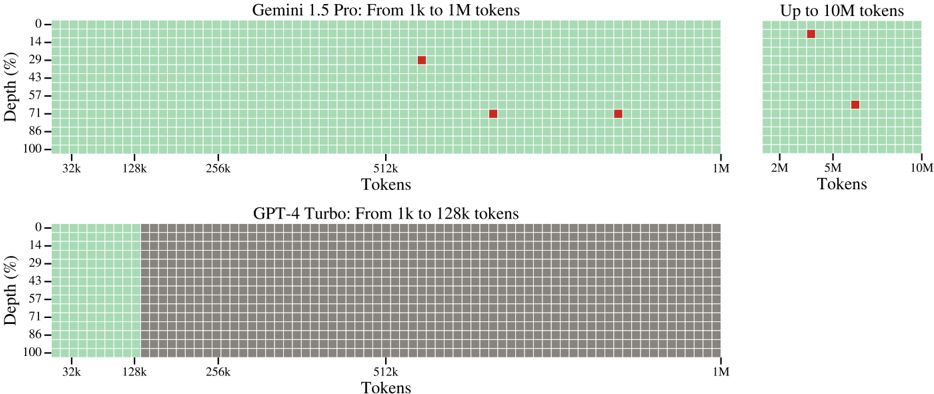
## Heatmap: Model Depth vs. Token Length
### Overview
The image presents two heatmaps comparing the depth (percentage) achieved by two language models, Gemini 1.5 Pro and GPT-4 Turbo, across varying token lengths. The heatmaps visually represent the model's ability to process information at different depths as the input token length increases. The Gemini 1.5 Pro heatmap covers token lengths from 1k to 10M, while the GPT-4 Turbo heatmap covers 1k to 128k.
### Components/Axes
* **X-axis (Horizontal):** Represents the token length.
* Gemini 1.5 Pro: 32k, 128k, 256k, 512k, 1M, 2M, 5M, 10M
* GPT-4 Turbo: 32k, 128k, 256k, 512k, 1M
* **Y-axis (Vertical):** Represents the depth, expressed as a percentage, ranging from 0% to 100%.
* **Color:** Represents the model's performance. Red indicates higher depth, while green indicates lower depth.
* **Titles:**
* Top: "Gemini 1.5 Pro: From 1k to 1M tokens" and "Up to 10M Tokens"
* Bottom: "GPT-4 Turbo: From 1k to 128k tokens"
### Detailed Analysis or Content Details
**Gemini 1.5 Pro:**
The heatmap shows a generally low depth for most token lengths. The trend is that depth increases with token length, but the increase is not consistent.
* 32k Tokens: Depth is approximately 0%.
* 128k Tokens: Depth is approximately 0%.
* 256k Tokens: Depth is approximately 0%.
* 512k Tokens: Depth is approximately 22% (± 2%).
* 1M Tokens: Depth is approximately 43% (± 2%).
* 2M Tokens: Depth is approximately 86% (± 2%).
* 5M Tokens: Depth is approximately 66% (± 2%).
* 10M Tokens: Depth is approximately 33% (± 2%).
**GPT-4 Turbo:**
The heatmap shows a consistently low depth across all token lengths.
* 32k Tokens: Depth is approximately 0%.
* 128k Tokens: Depth is approximately 0%.
* 256k Tokens: Depth is approximately 0%.
* 512k Tokens: Depth is approximately 0%.
* 1M Tokens: Depth is approximately 0%.
### Key Observations
* Gemini 1.5 Pro demonstrates a significantly higher depth than GPT-4 Turbo, especially at longer token lengths (2M tokens).
* For Gemini 1.5 Pro, the depth peaks at 2M tokens and then decreases at 5M and 10M tokens. This suggests an optimal token length for depth.
* GPT-4 Turbo shows minimal depth across the tested token lengths.
* The heatmap grid size is consistent across both models, allowing for a visual comparison of depth.
### Interpretation
The data suggests that Gemini 1.5 Pro has a substantially greater capacity for processing information at depth compared to GPT-4 Turbo, particularly as the input token length increases. The peak depth observed at 2M tokens for Gemini 1.5 Pro indicates a sweet spot where the model can effectively leverage longer contexts. The subsequent decrease in depth at 5M and 10M tokens could be due to several factors, such as computational limitations, attention decay, or the model's architecture.
The consistently low depth of GPT-4 Turbo suggests that it struggles to maintain context and process information effectively beyond shorter token lengths. This difference in performance highlights the advancements in model architecture and training techniques that enable Gemini 1.5 Pro to handle significantly longer contexts with greater depth.
The use of a heatmap effectively visualizes the relationship between token length and depth, allowing for a quick and intuitive understanding of each model's capabilities. The color gradient clearly distinguishes between areas of high and low depth, making it easy to identify optimal token lengths and performance limitations.