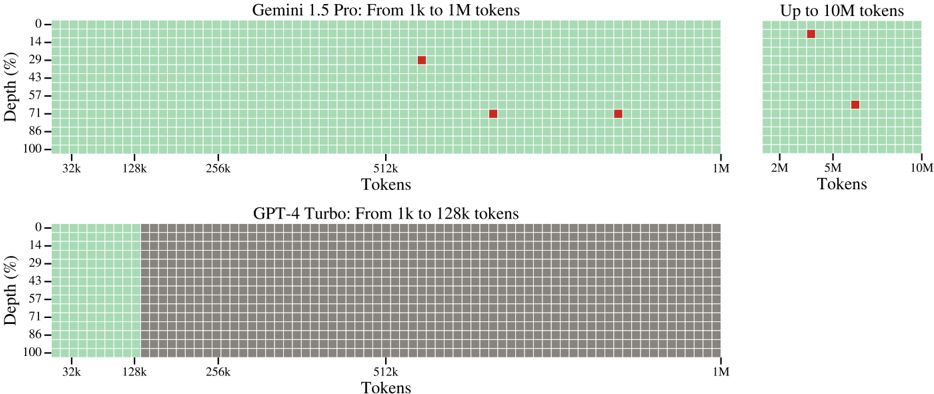
## Heatmaps: Token Depth Performance Comparison
### Overview
The image contains two heatmaps comparing token depth performance for AI models. The top heatmap analyzes **Gemini 1.5 Pro** across token ranges from 1k to 1M (with an inset extending to 10M tokens), while the bottom heatmap evaluates **GPT-4 Turbo** from 1k to 128k tokens. Both use a grid of green squares to represent data density, with red squares highlighting specific data points in the top heatmap.
---
### Components/Axes
#### Top Heatmap (Gemini 1.5 Pro)
- **X-axis (Tokens)**: Labeled "Tokens" with markers at 32k, 128k, 256k, 512k, 1M, and an inset extending to 10M.
- **Y-axis (Depth %)**: Labeled "Depth (%)" with increments at 0, 14, 29, 43, 57, 71, 86, and 100.
- **Legend**: Red squares represent data points for Gemini 1.5 Pro.
- **Inset**: A secondary heatmap on the right showing token ranges up to 10M.
#### Bottom Heatmap (GPT-4 Turbo)
- **X-axis (Tokens)**: Labeled "Tokens" with markers at 32k, 128k, 256k, 512k, 1M.
- **Y-axis (Depth %)**: Identical to the top heatmap (0–100%).
- **Color Coding**:
- Green section spans tokens 32k–128k and full depth (0–100%).
- Gray section spans tokens 128k–1M and full depth (0–100%).
---
### Detailed Analysis
#### Top Heatmap (Gemini 1.5 Pro)
- **Red Squares (Data Points)**:
- At **512k tokens**: Depths of **43%** and **71%**.
- At **1M tokens**: Depth of **71%**.
- Inset (10M tokens): Depth of **29%** at **5M tokens**.
- **Grid Pattern**: Mostly green, indicating uniform performance across most token-depth combinations, except for the highlighted red squares.
#### Bottom Heatmap (GPT-4 Turbo)
- **Green Section**: Covers tokens **32k–128k** and full depth (0–100%), suggesting consistent performance in this range.
- **Gray Section**: Covers tokens **128k–1M** and full depth (0–100%), indicating no data or lower performance beyond 128k tokens.
---
### Key Observations
1. **Gemini 1.5 Pro**:
- Demonstrates variable performance at specific token thresholds (e.g., 512k and 1M tokens).
- Performance drops significantly at 5M tokens (29% depth).
- The inset suggests limited data beyond 1M tokens, with sparse coverage up to 10M.
2. **GPT-4 Turbo**:
- Confined to token ranges up to **128k**, with no data beyond this limit.
- Full depth coverage (0–100%) within its operational range, but no performance data for higher tokens.
---
### Interpretation
- **Gemini 1.5 Pro** appears capable of handling larger token volumes (up to 10M) but shows reduced depth efficiency at extreme scales (e.g., 5M tokens). The red squares may indicate tested or optimized configurations.
- **GPT-4 Turbo** is restricted to smaller token ranges (<128k), with no evidence of performance beyond this threshold. The green section suggests consistent depth utilization within its operational limits.
- The heatmaps highlight trade-offs: Gemini 1.5 Pro offers scalability but with variable efficiency, while GPT-4 Turbo prioritizes consistency within a narrower scope.