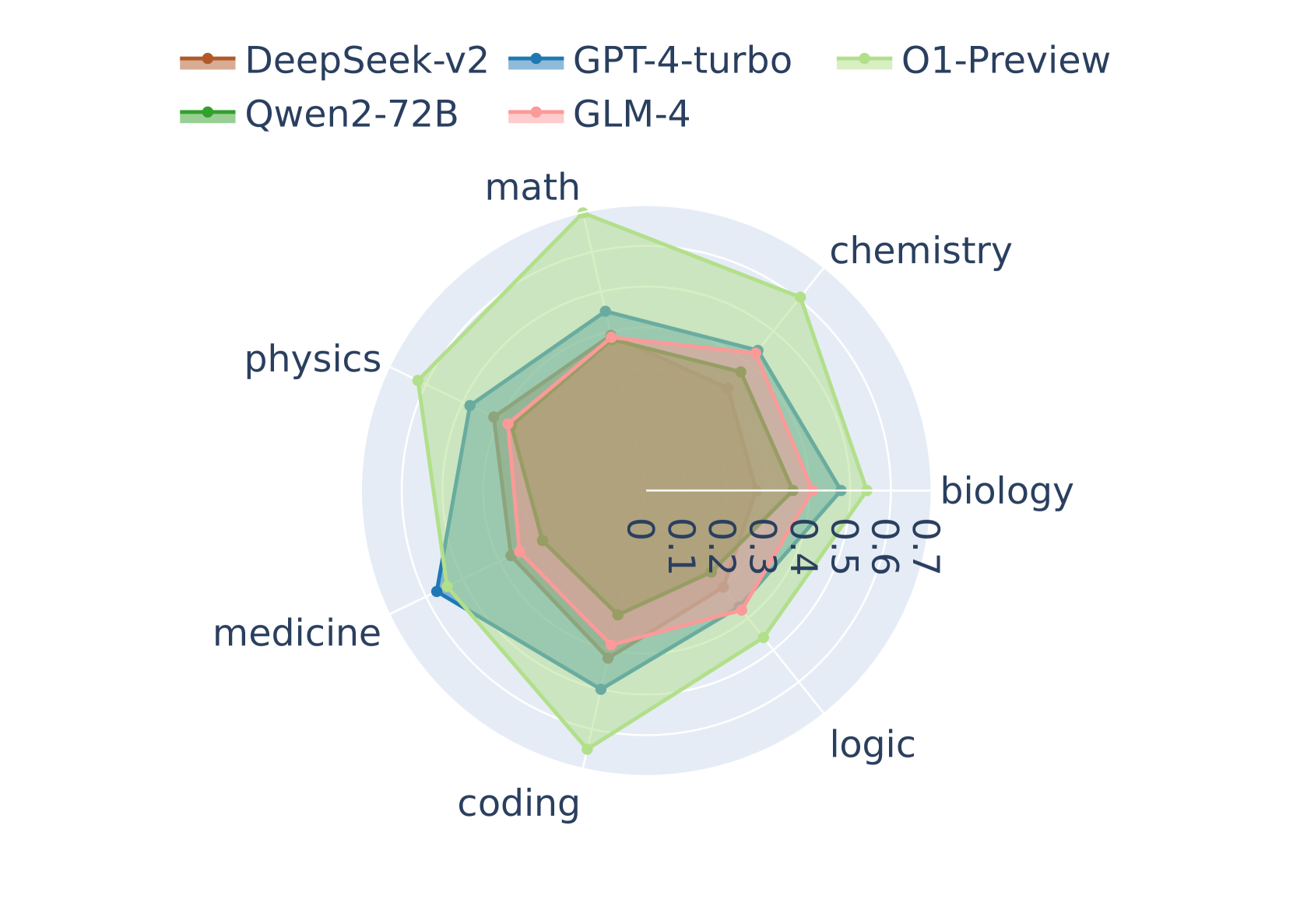
## Radar Chart: AI Model Performance Across Academic Disciplines
### Overview
The image is a radar chart comparing the performance of five AI models (DeepSeek-v2, GPT-4-turbo, O1-Preview, Qwen2-72B, GLM-4) across seven academic disciplines: math, chemistry, biology, logic, coding, medicine, and physics. The chart uses a circular layout with axes radiating from the center, each labeled with a subject. Data points are plotted for each model, with shaded areas indicating performance ranges.
### Components/Axes
- **Axes**:
- **Subjects**: math (top), chemistry (top-right), biology (right), logic (bottom-right), coding (bottom), medicine (bottom-left), physics (left).
- **Scale**: 0 to 0.7, with increments of 0.1.
- **Legend**:
- **Colors**:
- DeepSeek-v2: brown
- GPT-4-turbo: blue
- O1-Preview: light green
- Qwen2-72B: dark green
- GLM-4: pink
- **Position**: Top-left of the chart.
### Detailed Analysis
- **Math**:
- O1-Preview (0.7), Qwen2-72B (0.6), GPT-4-turbo (0.5), GLM-4 (0.4), DeepSeek-v2 (0.3).
- **Chemistry**:
- O1-Preview (0.65), Qwen2-72B (0.55), GPT-4-turbo (0.5), GLM-4 (0.45), DeepSeek-v2 (0.35).
- **Biology**:
- O1-Preview (0.6), Qwen2-72B (0.55), GPT-4-turbo (0.5), GLM-4 (0.5), DeepSeek-v2 (0.4).
- **Logic**:
- O1-Preview (0.55), Qwen2-72B (0.5), GPT-4-turbo (0.45), GLM-4 (0.4), DeepSeek-v2 (0.35).
- **Coding**:
- O1-Preview (0.7), Qwen2-72B (0.65), GPT-4-turbo (0.6), GLM-4 (0.55), DeepSeek-v2 (0.45).
- **Medicine**:
- GPT-4-turbo (0.7), O1-Preview (0.6), Qwen2-72B (0.55), GLM-4 (0.5), DeepSeek-v2 (0.4).
- **Physics**:
- O1-Preview (0.6), Qwen2-72B (0.6), GPT-4-turbo (0.55), GLM-4 (0.5), DeepSeek-v2 (0.45).
### Key Observations
1. **O1-Preview** dominates in **math** (0.7) and **coding** (0.7), with strong performance in **physics** (0.6) and **chemistry** (0.65).
2. **GPT-4-turbo** excels in **medicine** (0.7) and has balanced performance across other subjects.
3. **Qwen2-72B** performs well in **coding** (0.65) and **physics** (0.6), with moderate scores in other areas.
4. **GLM-4** shows the lowest performance in **math** (0.4) and **coding** (0.55), but matches others in **biology** (0.5).
5. **DeepSeek-v2** is the weakest across all subjects, with the lowest score in **math** (0.3).
### Interpretation
The chart highlights the **specialization** of AI models in specific disciplines. O1-Preview demonstrates the broadest competence, particularly in math and coding, suggesting it may be optimized for general-purpose problem-solving. GPT-4-turbo’s peak in medicine indicates a focus on biomedical or clinical applications. Qwen2-72B’s strength in coding and physics aligns with technical or computational tasks. GLM-4’s lower scores across most subjects suggest limitations in general knowledge, though it performs adequately in biology. DeepSeek-v2’s consistently low performance raises questions about its training data or architecture.
The data implies that **model selection** should depend on the target discipline: O1-Preview for math/coding, GPT-4-turbo for medicine, and Qwen2-72B for technical fields. GLM-4 and DeepSeek-v2 may require further refinement for broader applicability.