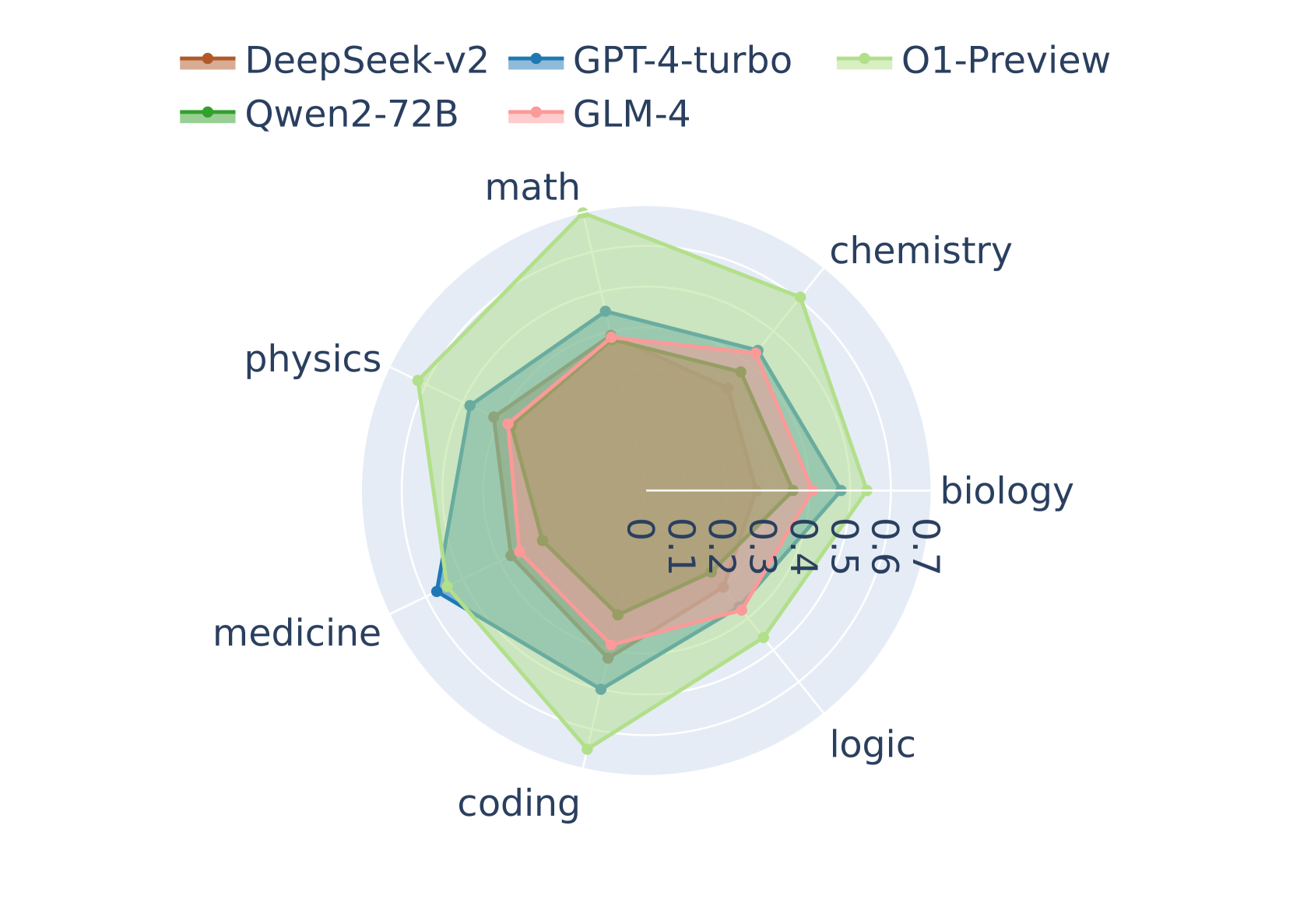
## Radar Chart: Model Performance Across Disciplines
### Overview
The image is a radar chart comparing the performance of five different models (DeepSeek-v2, GPT-4-turbo, O1-Preview, Qwen2-72B, and GLM-4) across seven disciplines: math, chemistry, biology, logic, coding, medicine, and physics. The chart visualizes the relative strengths and weaknesses of each model in these areas.
### Components/Axes
* **Axes:** The chart has seven radial axes, each representing a different discipline: math, chemistry, biology, logic, coding, medicine, and physics.
* **Scale:** The radial scale ranges from 0 to 0.7, with increments of 0.1.
* **Models (Legend):**
* DeepSeek-v2 (brown)
* GPT-4-turbo (blue)
* O1-Preview (light green)
* Qwen2-72B (green)
* GLM-4 (light red)
### Detailed Analysis
Here's a breakdown of each model's performance in each discipline:
* **DeepSeek-v2 (brown):**
* math: ~0.45
* chemistry: ~0.45
* biology: ~0.45
* logic: ~0.45
* coding: ~0.45
* medicine: ~0.45
* physics: ~0.45
* Trend: Relatively consistent performance across all disciplines.
* **GPT-4-turbo (blue):**
* math: ~0.3
* chemistry: ~0.3
* biology: ~0.3
* logic: ~0.3
* coding: ~0.1
* medicine: ~0.2
* physics: ~0.3
* Trend: Relatively consistent performance across most disciplines, with a dip in coding and medicine.
* **O1-Preview (light green):**
* math: ~0.65
* chemistry: ~0.7
* biology: ~0.7
* logic: ~0.7
* coding: ~0.7
* medicine: ~0.7
* physics: ~0.7
* Trend: Consistently high performance across all disciplines.
* **Qwen2-72B (green):**
* math: ~0.35
* chemistry: ~0.4
* biology: ~0.4
* logic: ~0.4
* coding: ~0.5
* medicine: ~0.4
* physics: ~0.4
* Trend: Relatively consistent performance across most disciplines, with a slight increase in coding.
* **GLM-4 (light red):**
* math: ~0.3
* chemistry: ~0.3
* biology: ~0.3
* logic: ~0.3
* coding: ~0.3
* medicine: ~0.3
* physics: ~0.3
* Trend: Consistent performance across all disciplines.
### Key Observations
* O1-Preview (light green) consistently outperforms the other models across all disciplines.
* DeepSeek-v2 (brown) shows relatively consistent performance across all disciplines, but at a lower level than O1-Preview.
* GPT-4-turbo (blue) has a noticeable dip in performance in coding compared to other disciplines.
* GLM-4 (light red) shows consistent performance across all disciplines.
* Qwen2-72B (green) shows a slight increase in coding performance compared to other disciplines.
### Interpretation
The radar chart provides a visual comparison of the strengths and weaknesses of different models across various academic disciplines. O1-Preview appears to be the most versatile and high-performing model, while the other models exhibit varying degrees of specialization or consistent performance at lower levels. The chart highlights the importance of considering specific domain requirements when selecting a model, as some models may excel in certain areas while underperforming in others. The consistent performance of DeepSeek-v2 and GLM-4 suggests a balanced approach, while the dip in GPT-4-turbo's coding performance indicates a potential area for improvement or a trade-off in its design.