\n
## Radar Chart: Model Performance Across Disciplines
### Overview
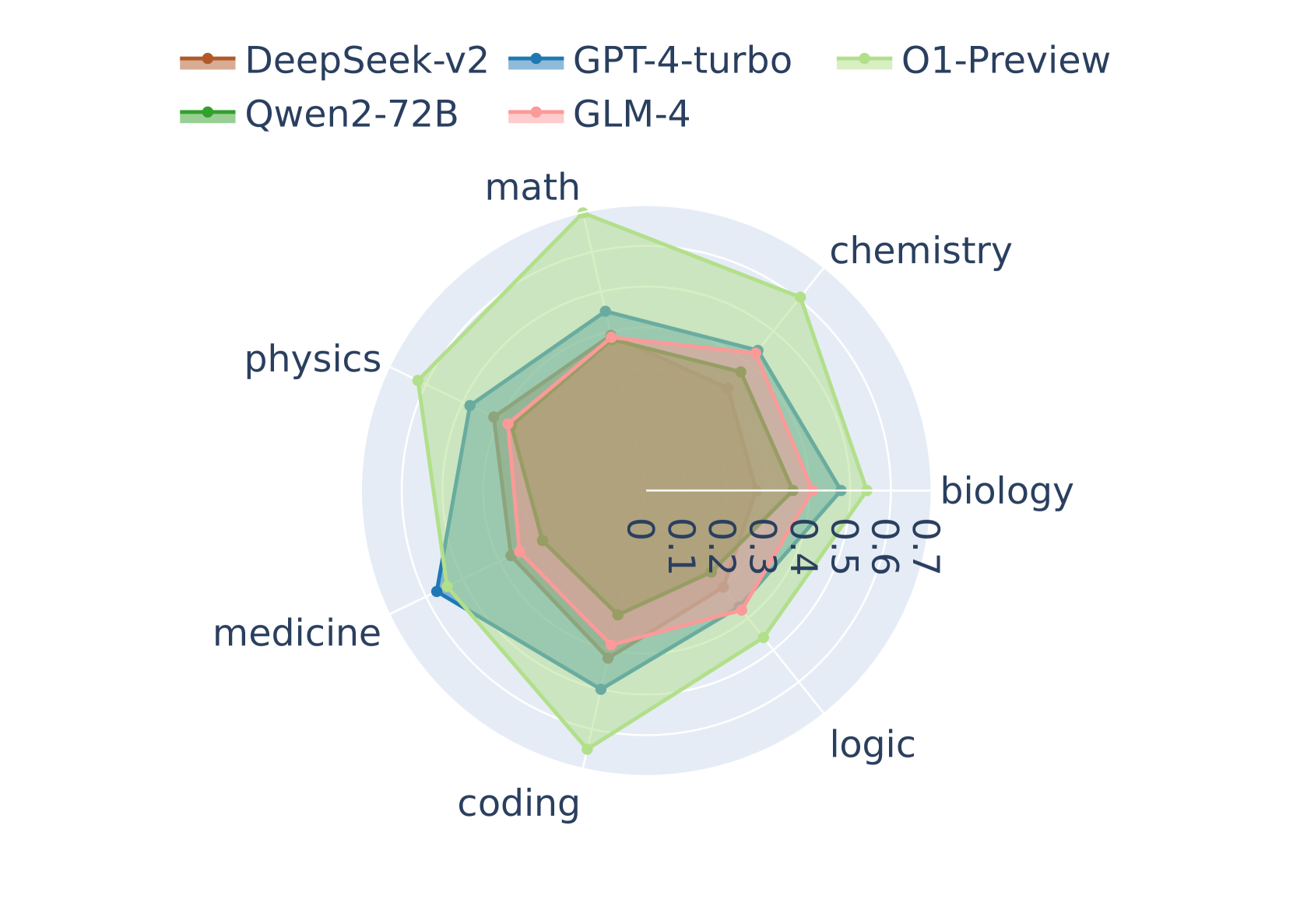
This image presents a radar chart comparing the performance of six different models – DeepSeek-v2, GPT-4-turbo, O1-Preview, Qwen2-72B, GLM-4 – across six disciplines: math, chemistry, biology, logic, coding, and medicine. The performance is represented on a scale from 0 to 7.
### Components/Axes
* **Axes:** Six radial axes, each representing a discipline: math, chemistry, biology, logic, coding, and medicine. The axes are labeled clockwise starting from the top.
* **Scale:** The scale ranges from 0 to 7, marked at intervals of 1 along each axis.
* **Legend:** Located at the top-right of the chart, the legend maps colors to models:
* DeepSeek-v2 (Orange)
* GPT-4-turbo (Red)
* O1-Preview (Light Green)
* Qwen2-72B (Dark Green)
* GLM-4 (Pink)
### Detailed Analysis
The chart displays a polygon for each model, representing its performance across the six disciplines. The further a polygon extends along an axis, the higher the model's performance in that discipline.
* **DeepSeek-v2 (Orange):** The polygon for DeepSeek-v2 shows moderate performance across all disciplines. It peaks at approximately 6.5 in math and chemistry, and dips to around 3 in medicine.
* **GPT-4-turbo (Red):** GPT-4-turbo exhibits a relatively consistent performance across all disciplines, ranging from approximately 4 to 6. It shows a slight peak in math and chemistry, around 6.
* **O1-Preview (Light Green):** O1-Preview demonstrates the highest overall performance, with values consistently above 6. It peaks at approximately 7 in math and chemistry, and maintains a value of around 6 in other disciplines.
* **Qwen2-72B (Dark Green):** Qwen2-72B shows a similar pattern to DeepSeek-v2, with moderate performance across all disciplines. It peaks at approximately 6 in math and chemistry, and dips to around 3 in medicine.
* **GLM-4 (Pink):** GLM-4 shows a relatively consistent performance across all disciplines, ranging from approximately 3 to 5. It shows a slight peak in math and chemistry, around 5.
* **Math:** O1-Preview and DeepSeek-v2 are the highest performers, both around 7. GPT-4-turbo, Qwen2-72B, and GLM-4 are around 6, and 5 respectively.
* **Chemistry:** O1-Preview and DeepSeek-v2 are the highest performers, both around 7. GPT-4-turbo, Qwen2-72B, and GLM-4 are around 6, and 5 respectively.
* **Biology:** O1-Preview is the highest performer, around 6.5. GPT-4-turbo and Qwen2-72B are around 5.5, and DeepSeek-v2 and GLM-4 are around 4.
* **Logic:** O1-Preview is the highest performer, around 6.5. GPT-4-turbo and Qwen2-72B are around 5.5, and DeepSeek-v2 and GLM-4 are around 4.
* **Coding:** O1-Preview is the highest performer, around 6.5. GPT-4-turbo and Qwen2-72B are around 5.5, and DeepSeek-v2 and GLM-4 are around 4.
* **Medicine:** O1-Preview is the highest performer, around 6. GPT-4-turbo and Qwen2-72B are around 5, and DeepSeek-v2 and GLM-4 are around 3.
### Key Observations
* O1-Preview consistently outperforms other models across all disciplines.
* DeepSeek-v2 and Qwen2-72B exhibit similar performance profiles.
* GLM-4 generally shows the lowest performance across all disciplines.
* All models perform best in math and chemistry, and worst in medicine.
### Interpretation
The radar chart effectively visualizes the relative strengths and weaknesses of each model across a diverse set of disciplines. O1-Preview emerges as the most versatile model, demonstrating strong performance in all areas. The consistent performance of GPT-4-turbo suggests a balanced skillset. The similarities between DeepSeek-v2 and Qwen2-72B indicate they may share underlying architectural or training characteristics. The lower scores of GLM-4 suggest it may require further development or specialization to compete with the other models. The consistent trend of higher scores in math and chemistry, and lower scores in medicine, could indicate a bias in the training data or a greater inherent difficulty in the medicine domain. This chart provides a valuable comparative analysis for selecting the most appropriate model for a given task or application.