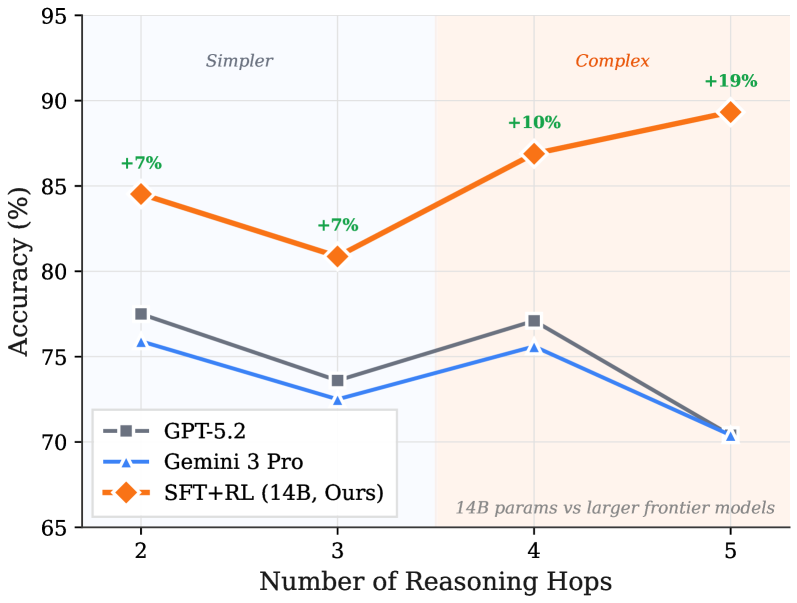
## Line Chart: Model Accuracy vs. Number of Reasoning Hops
### Overview
The image is a line chart comparing the accuracy of three different language models (GPT-5.2, Gemini 3 Pro, and SFT+RL (14B, Ours)) across varying numbers of reasoning hops (2 to 5). The chart is divided into two regions, labeled "Simpler" and "Complex," with the SFT+RL model showing performance gains as the complexity increases.
### Components/Axes
* **X-axis:** "Number of Reasoning Hops," with values 2, 3, 4, and 5.
* **Y-axis:** "Accuracy (%)", ranging from 65 to 95 in increments of 5.
* **Legend:** Located in the lower-left corner, identifying the models:
* GPT-5.2 (gray line with square markers)
* Gemini 3 Pro (blue line with triangle markers)
* SFT+RL (14B, Ours) (orange line with diamond markers)
* **Regions:** The chart is divided into two vertical regions:
* Left region: Labeled "Simpler" with a light blue background.
* Right region: Labeled "Complex" with a light orange background.
* **Annotation:** "14B params vs larger frontier models" is written in the bottom-right corner.
* **Accuracy Increase Labels:** Green labels indicating the percentage increase in accuracy for the SFT+RL model at specific reasoning hops.
### Detailed Analysis
**1. GPT-5.2 (Gray Line):**
* Trend: Generally decreasing accuracy with increasing reasoning hops.
* Data Points:
* 2 hops: ~77%
* 3 hops: ~73%
* 4 hops: ~77%
* 5 hops: ~70%
**2. Gemini 3 Pro (Blue Line):**
* Trend: Decreasing accuracy with increasing reasoning hops.
* Data Points:
* 2 hops: ~76%
* 3 hops: ~72%
* 4 hops: ~76%
* 5 hops: ~70%
**3. SFT+RL (14B, Ours) (Orange Line):**
* Trend: Increasing accuracy with increasing reasoning hops.
* Data Points:
* 2 hops: ~84% (+7% annotation)
* 3 hops: ~81% (+7% annotation)
* 4 hops: ~87% (+10% annotation)
* 5 hops: ~89% (+19% annotation)
### Key Observations
* The SFT+RL model consistently outperforms GPT-5.2 and Gemini 3 Pro across all reasoning hops.
* The SFT+RL model shows a significant increase in accuracy as the number of reasoning hops increases, particularly in the "Complex" region.
* GPT-5.2 and Gemini 3 Pro show a slight decrease in accuracy as the number of reasoning hops increases.
* The annotations indicate the percentage increase in accuracy for the SFT+RL model compared to its performance at 2 reasoning hops.
### Interpretation
The chart suggests that the SFT+RL model is better suited for complex reasoning tasks compared to GPT-5.2 and Gemini 3 Pro. The increasing accuracy of the SFT+RL model with more reasoning hops indicates its ability to effectively handle more complex problems. The "Simpler" and "Complex" regions highlight that the SFT+RL model's advantage becomes more pronounced as the task complexity increases. The annotation "14B params vs larger frontier models" suggests that the SFT+RL model achieves competitive performance despite having fewer parameters than other frontier models, indicating a more efficient use of its parameters for reasoning tasks. The performance of GPT-5.2 and Gemini 3 Pro decreases slightly with more reasoning hops, suggesting they may struggle with more complex tasks.