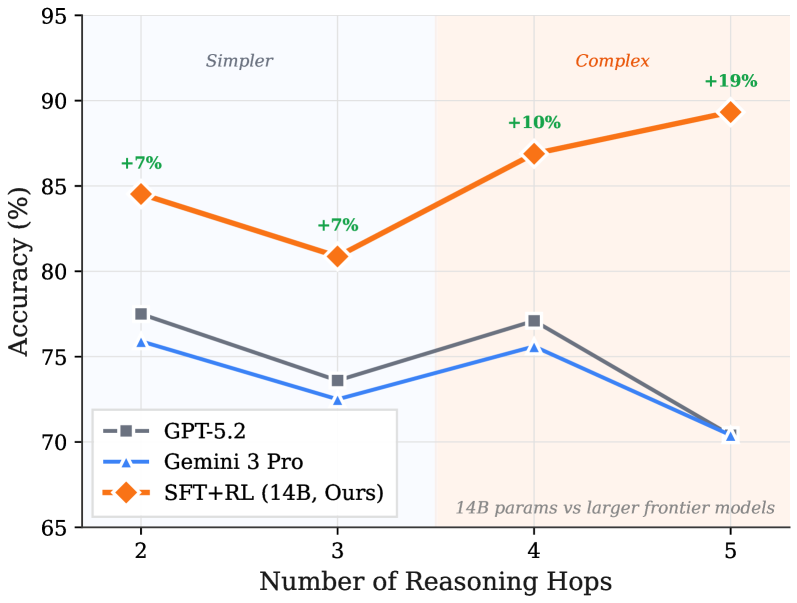
## Line Chart: Model Accuracy vs. Number of Reasoning Hops
### Overview
The chart compares the accuracy of three AI models (GPT-5.2, Gemini 3 Pro, and SFT+RL) across 2–5 reasoning hops. Accuracy is plotted on the y-axis (65–95%), while the x-axis represents the number of reasoning hops (2–5). The chart is divided into two regions: "Simpler" (left, blue) and "Complex" (right, orange). The SFT+RL model (orange line) shows the highest accuracy, with notable percentage increases (+7%, +7%, +10%, +19%) annotated at each hop.
### Components/Axes
- **X-axis**: "Number of Reasoning Hops" (2, 3, 4, 5).
- **Y-axis**: "Accuracy (%)" (65–95%).
- **Legend**:
- Gray square: GPT-5.2
- Blue triangle: Gemini 3 Pro
- Orange diamond: SFT+RL (14B, Ours)
- **Regions**:
- Left (blue): "Simpler"
- Right (orange): "Complex"
### Detailed Analysis
1. **GPT-5.2** (gray line):
- Hop 2: ~77.5%
- Hop 3: ~73.5%
- Hop 4: ~77%
- Hop 5: ~70.5%
- Trend: Initial drop, slight recovery, then sharp decline.
2. **Gemini 3 Pro** (blue line):
- Hop 2: ~75.5%
- Hop 3: ~72%
- Hop 4: ~75.5%
- Hop 5: ~70.5%
- Trend: Volatile, with no clear upward trajectory.
3. **SFT+RL (14B, Ours)** (orange line):
- Hop 2: ~84.5% (+7%)
- Hop 3: ~81.5% (+7%)
- Hop 4: ~87% (+10%)
- Hop 5: ~89.5% (+19%)
- Trend: Steady upward slope in the "Complex" region.
### Key Observations
- SFT+RL consistently outperforms other models, especially in the "Complex" region (hops 4–5).
- GPT-5.2 and Gemini 3 Pro show declining accuracy with more hops, while SFT+RL improves.
- Percentage increases for SFT+RL are highest in the "Complex" region (+19% at hop 5).
### Interpretation
The data demonstrates that SFT+RL (14B) excels in complex reasoning tasks, with accuracy gains accelerating as the number of hops increases. This suggests its architecture is better suited for multi-step reasoning compared to GPT-5.2 and Gemini 3 Pro, which degrade in performance under similar conditions. The "Complex" region’s orange shading emphasizes the model’s scalability, while the "Simpler" region highlights baseline performance. The percentage annotations (+7%, +19%) underscore SFT+RL’s efficiency in leveraging additional reasoning steps for higher accuracy.