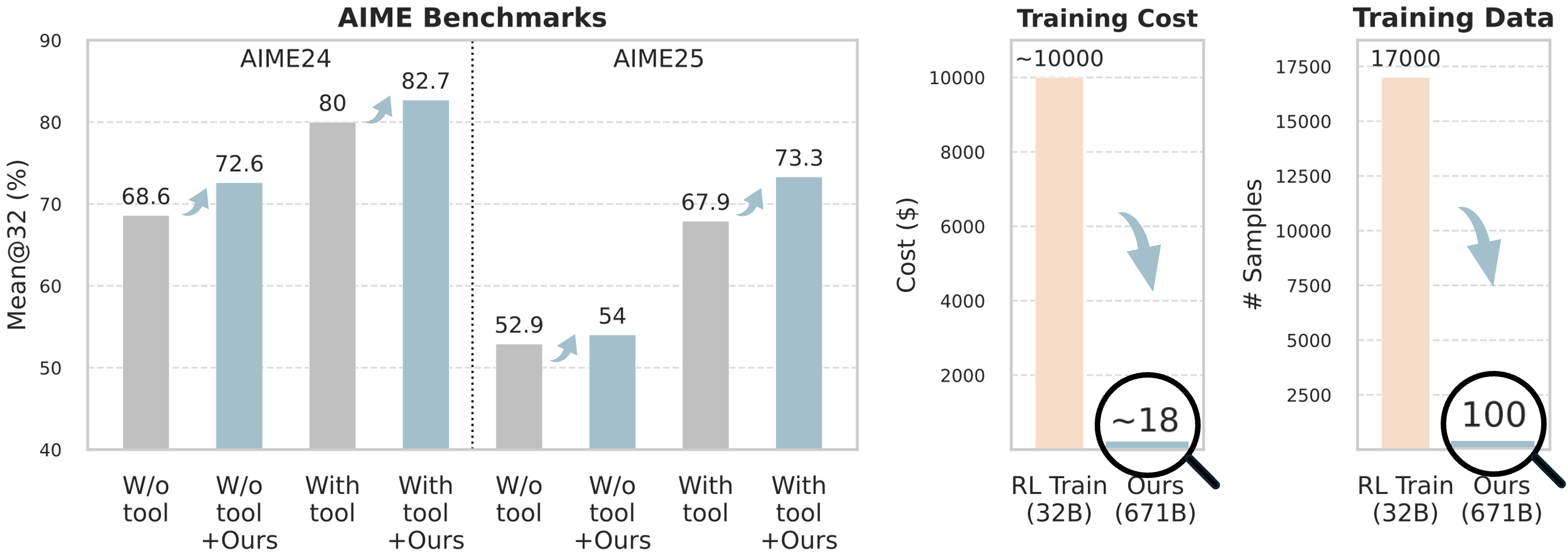
## Bar Charts: AIME Benchmarks, Training Cost, and Training Data
### Overview
The image presents three sets of bar charts comparing performance metrics for a model ("Ours") against a baseline ("W/o tool") and a baseline with an additional component ("W/o tool + Ours"). The charts cover AIME24 and AIME25 benchmarks (Mean@32), Training Cost, and Training Data (# Samples). Arrows indicate relative changes between data points.
### Components/Axes
* **AIME Benchmarks:**
* X-axis: Categories - "W/o tool", "W/o tool + Ours", "With tool", "With tool + Ours" (repeated for AIME24 and AIME25).
* Y-axis: "Mean@32 (%)", ranging from 40 to 90.
* **Training Cost:**
* X-axis: Categories - "RL Train (32B)", "Ours (671B)".
* Y-axis: "Cost ($)", ranging from 0 to 10000.
* **Training Data:**
* X-axis: Categories - "RL Train (32B)", "Ours (671B)".
* Y-axis: "# Samples", ranging from 0 to 17500.
* **Arrows:** Downward arrows indicate a decrease in value, while upward arrows indicate an increase.
* **Circles:** Highlight specific values with approximate numbers inside.
### Detailed Analysis or Content Details
**AIME Benchmarks:**
* **AIME24:**
* "W/o tool": Approximately 68.6%.
* "W/o tool + Ours": Approximately 72.6%.
* "With tool": Approximately 80%.
* "With tool + Ours": Approximately 82.7%.
* Trend: Performance increases consistently with the addition of "tool" and "Ours".
* **AIME25:**
* "W/o tool": Approximately 52.9%.
* "W/o tool + Ours": Approximately 54%.
* "With tool": Approximately 67.9%.
* "With tool + Ours": Approximately 73.3%.
* Trend: Similar to AIME24, performance increases with the addition of "tool" and "Ours".
**Training Cost:**
* "RL Train (32B)": Approximately 10000$.
* "Ours (671B)": Approximately 18$.
* Trend: A significant decrease in cost when using "Ours".
**Training Data:**
* "RL Train (32B)": Approximately 17000 samples.
* "Ours (671B)": Approximately 100 samples.
* Trend: A significant decrease in the number of samples required when using "Ours".
### Key Observations
* The addition of both "tool" and "Ours" consistently improves performance on both AIME benchmarks.
* Using "Ours" dramatically reduces both training cost and the amount of training data needed.
* The cost reduction is particularly striking, with "Ours" costing approximately 18$ compared to 10000$ for "RL Train (32B)".
* The reduction in training data is also substantial, with "Ours" requiring only 100 samples compared to 17000 for "RL Train (32B)".
### Interpretation
The data suggests that the "Ours" model, potentially in conjunction with a "tool", offers a significant improvement in performance on the AIME benchmarks while simultaneously reducing training costs and data requirements. This indicates a more efficient and effective learning process. The large difference in cost and data suggests that "Ours" may leverage techniques like transfer learning, data augmentation, or more efficient optimization algorithms. The consistent performance gains across both AIME24 and AIME25 suggest the benefits are not specific to a particular benchmark. The downward arrows visually emphasize the positive impact of "Ours" on cost and data usage, reinforcing the message of efficiency. The use of "B" in the model sizes (32B, 671B) likely refers to the number of parameters in the model, indicating that "Ours" is a much larger model, but its efficiency mitigates the expected increase in training cost.