# Technical Document Extraction: Image Analysis
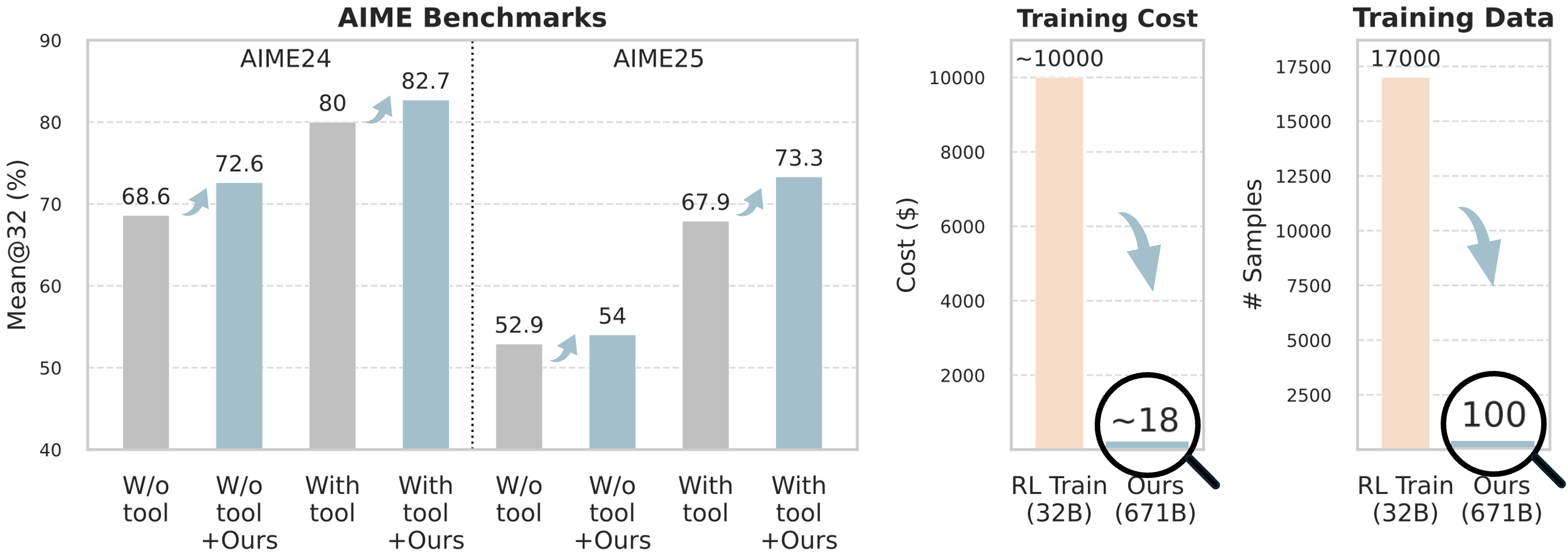
## Chart 1: AIME Benchmarks
### Title
- **Title**: AIME Benchmarks
### Axes
- **X-Axis**:
- Categories:
- `W/o tool`
- `W/o tool + Ours`
- `With tool`
- `With tool + Ours`
- Grouped by: `AIME24` (left) and `AIME25` (right)
- **Y-Axis**:
- Label: `Mean@32 (%)`
- Range: 40–90
### Data Points & Trends
- **AIME24**:
- `W/o tool`: 68.6% (gray bar, no arrow)
- `W/o tool + Ours`: 72.6% (blue bar, ↑ arrow)
- `With tool`: 80% (gray bar, no arrow)
- `With tool + Ours`: 82.7% (blue bar, ↑ arrow)
- **AIME25**:
- `W/o tool`: 52.9% (gray bar, no arrow)
- `W/o tool + Ours`: 54% (blue bar, ↑ arrow)
- `With tool`: 67.9% (gray bar, no arrow)
- `With tool + Ours`: 73.3% (blue bar, ↑ arrow)
### Legend
- **Placement**: Not explicitly visible (assumed grouped by color).
- **Colors**:
- Gray: Baseline (no tool)
- Blue: Enhanced (with tool + Ours)
### Key Observations
- **Trend Verification**:
- All "With tool + Ours" bars show upward trends (↑ arrows).
- AIME25 performance is consistently lower than AIME24 across all categories.
---
## Chart 2: Training Cost
### Title
- **Title**: Training Cost
### Axes
- **X-Axis**:
- Categories:
- `RL Train (32B)`
- `Ours (671B)`
- **Y-Axis**:
- Label: `Cost ($)`
- Range: 0–10,000
### Data Points & Trends
- **RL Train (32B)**: ~10,000$ (peach bar, no arrow)
- **Ours (671B)**: ~18$ (blue bar, ↓ arrow)
- **Magnifying Glass**: Highlights the drastic cost reduction (~18$).
### Legend
- **Placement**: Right side.
- **Colors**:
- Peach: RL Train (32B)
- Blue: Ours (671B)
### Key Observations
- **Trend Verification**:
- Ours (671B) shows a significant cost reduction (↓ arrow).
- RL Train (32B) is ~555x more expensive than Ours.
---
## Chart 3: Training Data
### Title
- **Title**: Training Data
### Axes
- **X-Axis**:
- Categories:
- `RL Train (32B)`
- `Ours (671B)`
- **Y-Axis**:
- Label: `# Samples`
- Range: 0–17,500
### Data Points & Trends
- **RL Train (32B)**: ~17,000 samples (peach bar, no arrow)
- **Ours (671B)**: ~100 samples (blue bar, ↓ arrow)
- **Magnifying Glass**: Highlights the drastic sample reduction (~100).
### Legend
- **Placement**: Right side.
- **Colors**:
- Peach: RL Train (32B)
- Blue: Ours (671B)
### Key Observations
- **Trend Verification**:
- Ours (671B) shows a significant sample reduction (↓ arrow).
- RL Train (32B) uses ~170x more samples than Ours.
---
## Summary of Key Trends
1. **AIME Benchmarks**:
- Enhanced models (`+ Ours`) improve performance across all categories.
- AIME25 lags behind AIME24 in baseline performance but shows similar improvement with enhancements.
2. **Training Cost**:
- Ours (671B) reduces cost by ~555x compared to RL Train (32B).
3. **Training Data**:
- Ours (671B) reduces training data by ~170x compared to RL Train (32B).
## Spatial Grounding & Component Isolation
- **AIME Benchmarks**:
- Header: "AIME Benchmarks"
- Main Chart: Grouped bars for AIME24/AIME25.
- Footer: No explicit footer.
- **Training Cost**:
- Header: "Training Cost"
- Main Chart: Bar comparison.
- Footer: Magnifying glass highlighting Ours (671B).
- **Training Data**:
- Header: "Training Data"
- Main Chart: Bar comparison.
- Footer: Magnifying glass highlighting Ours (671B).
## Final Notes
- All charts use consistent color coding (gray/peach for baseline, blue for enhanced).
- No textual data tables or non-English content present.
- All numerical values and trends are explicitly labeled or visually indicated.