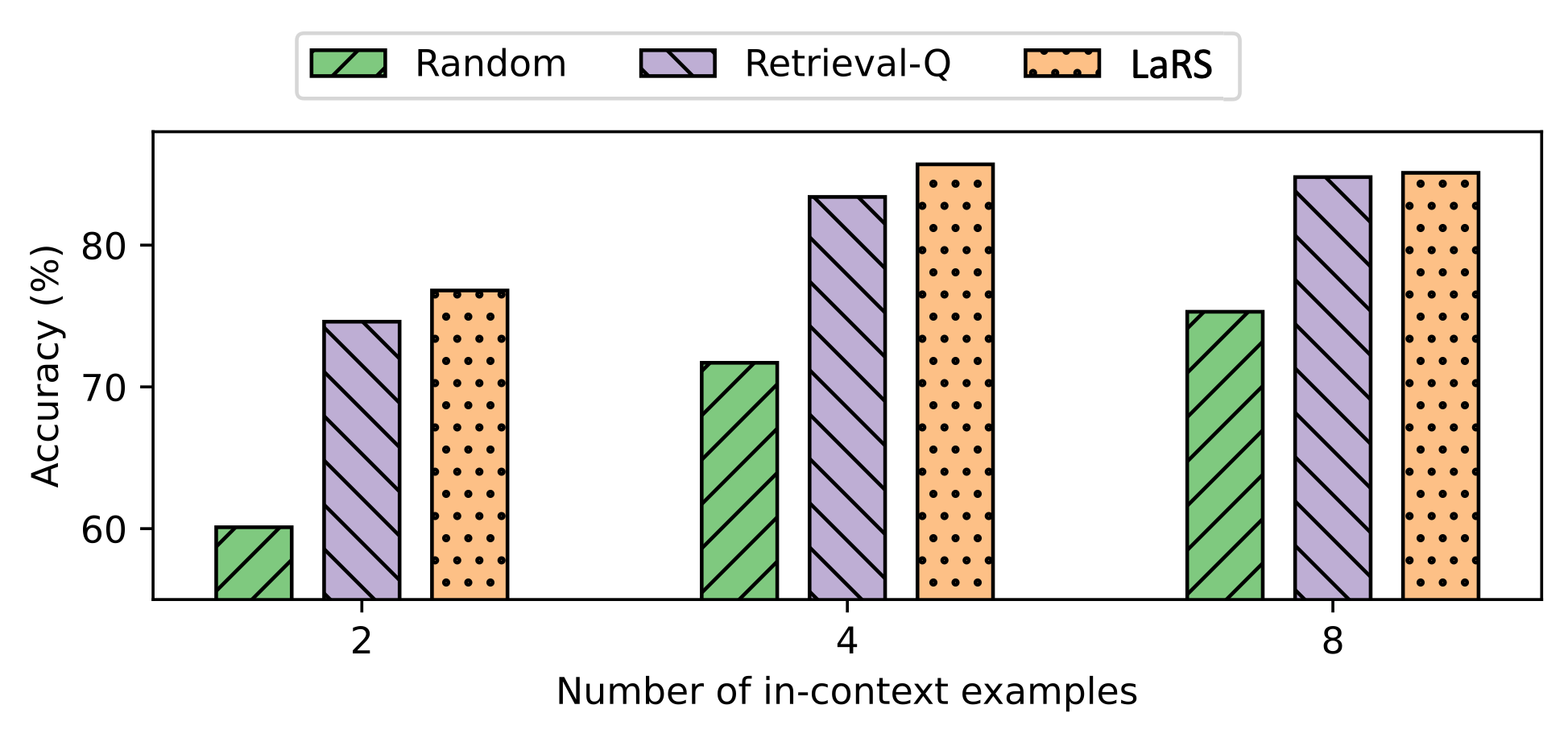
## Bar Chart: Accuracy Comparison Across In-Context Examples
### Overview
The chart compares the accuracy (%) of three methods—Random, Retrieval-Q, and LaRS—across three scenarios defined by the number of in-context examples (2, 4, 8). Accuracy is measured on the y-axis (55–90%), while the x-axis categorizes data by the number of examples. Each method is represented by a distinct color and pattern: green (Random), purple (Retrieval-Q), and orange (LaRS).
### Components/Axes
- **X-axis**: "Number of in-context examples" with categories: 2, 4, 8.
- **Y-axis**: "Accuracy (%)" ranging from 55% to 90%.
- **Legend**:
- Green (diagonal stripes): Random
- Purple (diagonal stripes): Retrieval-Q
- Orange (dots): LaRS
- **Bar Groups**: Three clusters of bars, one for each x-axis category (2, 4, 8), with three bars per cluster (one per method).
### Detailed Analysis
- **At 2 in-context examples**:
- Random: ~60% accuracy (green bar).
- Retrieval-Q: ~75% accuracy (purple bar).
- LaRS: ~77% accuracy (orange bar).
- **At 4 in-context examples**:
- Random: ~72% accuracy (green bar).
- Retrieval-Q: ~84% accuracy (purple bar).
- LaRS: ~88% accuracy (orange bar).
- **At 8 in-context examples**:
- Random: ~75% accuracy (green bar).
- Retrieval-Q: ~86% accuracy (purple bar).
- LaRS: ~87% accuracy (orange bar).
### Key Observations
1. **Trends**:
- All methods show increasing accuracy with more in-context examples.
- LaRS and Retrieval-Q consistently outperform Random across all example counts.
- LaRS and Retrieval-Q achieve near-identical accuracy at 8 examples (~87% vs. ~86%).
2. **Notable Patterns**:
- Random’s accuracy plateaus at ~75% even with 8 examples, suggesting limited benefit from additional context.
- LaRS and Retrieval-Q demonstrate diminishing returns between 4 and 8 examples (e.g., LaRS drops from ~88% to ~87%).
### Interpretation
The data suggests that **LaRS and Retrieval-Q leverage in-context examples more effectively than Random**, likely due to structured retrieval or reasoning mechanisms. While all methods improve with more examples, the marginal gains for LaRS and Retrieval-Q at higher example counts imply potential saturation or diminishing utility of additional context. The slight edge of LaRS over Retrieval-Q at 4 examples (~88% vs. ~84%) may reflect architectural differences, but their convergence at 8 examples hints at similar performance ceilings. Random’s stagnation at ~75% underscores its inefficiency in utilizing context, possibly due to lack of targeted example selection.