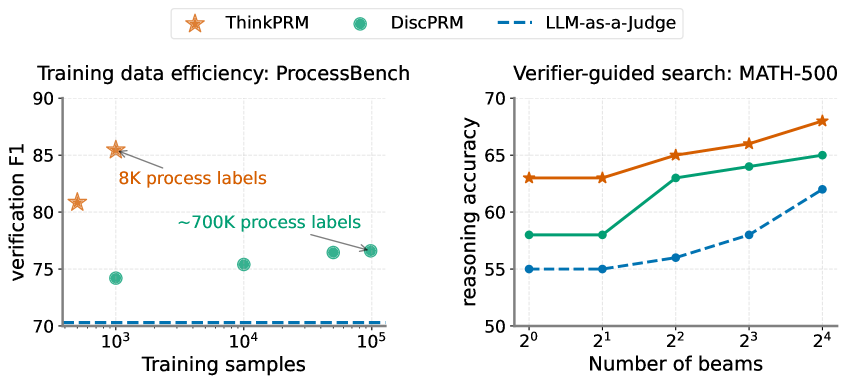
## Line Charts: Training Data Efficiency and Verifier-Guided Search Performance
### Overview
The image contains two line charts comparing the performance of three AI systems: ThinkPRM (orange stars), DiscPRM (green circles), and LLM-as-a-Judge (blue dashed line). The left chart focuses on training data efficiency using ProcessBench, while the right chart examines verifier-guided search performance on MATH-500.
### Components/Axes
**Left Chart (ProcessBench):**
- **X-axis**: Training samples (logarithmic scale: 10³ to 10⁵)
- **Y-axis**: Verification F1 score (70–90)
- **Legend**:
- Orange star: ThinkPRM
- Green circle: DiscPRM
- Blue dashed line: LLM-as-a-Judge
- **Key annotations**:
- "8K process labels" (ThinkPRM)
- "~700K process labels" (DiscPRM)
**Right Chart (MATH-500):**
- **X-axis**: Number of beams (2⁰ to 2⁴)
- **Y-axis**: Reasoning accuracy (50–70)
- **Legend**: Same as left chart
- **Trend**: All lines show upward trajectories
### Detailed Analysis
**Left Chart Trends:**
1. **ThinkPRM**:
- Starts at ~85 F1 with 8K samples (orange star)
- Drops to ~80 F1 at ~700K samples (orange star)
2. **DiscPRM**:
- Starts at ~75 F1 with 10³ samples (green circle)
- Increases to ~76 F1 at ~700K samples (green circle)
3. **LLM-as-a-Judge**:
- Flat line at ~70 F1 across all sample sizes
**Right Chart Trends:**
1. **ThinkPRM**:
- Starts at ~63 accuracy with 2⁰ beams
- Rises to ~68 accuracy with 2⁴ beams
2. **DiscPRM**:
- Starts at ~58 accuracy with 2⁰ beams
- Increases to ~65 accuracy with 2⁴ beams
3. **LLM-as-a-Judge**:
- Starts at ~55 accuracy with 2⁰ beams
- Rises to ~62 accuracy with 2⁴ beams
### Key Observations
1. **Training Efficiency**:
- ThinkPRM achieves highest F1 with minimal data (8K samples)
- DiscPRM requires ~700K samples to reach ~76 F1
- LLM-as-a-Judge shows no improvement with more data
2. **Verifier-Guided Search**:
- All systems improve with more beams
- ThinkPRM gains 5.7 accuracy points (2⁰→2⁴)
- DiscPRM gains 7 accuracy points (2⁰→2⁴)
- LLM-as-a-Judge gains 7 accuracy points (2⁰→2⁴)
3. **Performance Gaps**:
- ThinkPRM maintains 10–15 point advantage over others in both tasks
- LLM-as-a-Judge shows strongest relative improvement (+7 points) in MATH-500
### Interpretation
The data suggests ThinkPRM demonstrates superior efficiency and scalability across both tasks. Its ability to maintain high performance with limited training data (8K samples) while still benefiting from increased computational resources (beams) indicates architectural advantages. The LLM-as-a-Judge's flat performance in ProcessBench but strong improvement in MATH-500 suggests task-specific limitations in its reasoning capabilities. The consistent performance gap between ThinkPRM and other systems highlights potential for further optimization in existing models, particularly in balancing data efficiency with computational resource utilization.