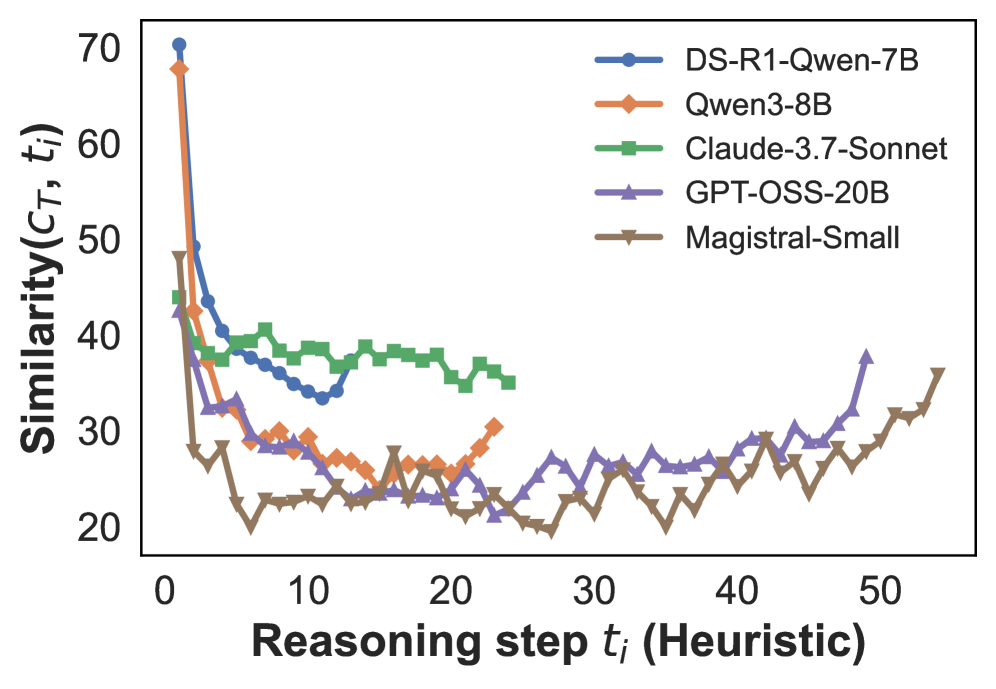
## Line Chart: Similarity vs. Reasoning Step
### Overview
This image presents a line chart illustrating the similarity (Similarity(Cτ, t)) of different language models over reasoning steps (t). The chart compares the performance of DS-R1-Qwen-7B, Qwen-3-8B, Claude-3.7-Sonnet, GPT-OSS-20B, and Magistral-Small as the number of reasoning steps increases.
### Components/Axes
* **X-axis:** Reasoning step tᵢ (Heuristic). Scale ranges from approximately 0 to 55.
* **Y-axis:** Similarity(Cτ, t). Scale ranges from approximately 20 to 70.
* **Legend:** Located in the top-right corner, identifying each line with a corresponding color:
* DS-R1-Qwen-7B (Blue)
* Qwen-3-8B (Orange)
* Claude-3.7-Sonnet (Green)
* GPT-OSS-20B (Purple)
* Magistral-Small (Brown)
### Detailed Analysis
Here's a breakdown of each line's trend and approximate data points:
* **DS-R1-Qwen-7B (Blue):** The line starts at approximately 68 at step 0, rapidly decreases to around 35 by step 5, then fluctuates between approximately 30 and 40 for steps 5 to 45. It then shows an upward trend, reaching approximately 40 at step 55.
* **Qwen-3-8B (Orange):** Starts at approximately 60 at step 0, quickly drops to around 25 by step 5, and remains relatively stable between approximately 22 and 30 for steps 5 to 45. It shows a slight increase to approximately 30 at step 55.
* **Claude-3.7-Sonnet (Green):** Begins at approximately 65 at step 0, decreases to around 38 by step 5, and maintains a relatively constant level between approximately 34 and 40 for steps 5 to 55.
* **GPT-OSS-20B (Purple):** Starts at approximately 62 at step 0, declines to around 28 by step 5, and fluctuates between approximately 25 and 35 for steps 5 to 55.
* **Magistral-Small (Brown):** Starts at approximately 55 at step 0, drops to around 22 by step 5, and remains relatively stable between approximately 20 and 30 for steps 5 to 55.
### Key Observations
* All models exhibit a significant drop in similarity within the first 5 reasoning steps.
* Claude-3.7-Sonnet maintains the highest similarity scores throughout most of the reasoning steps, remaining relatively stable.
* Magistral-Small consistently shows the lowest similarity scores.
* DS-R1-Qwen-7B shows the most significant increase in similarity towards the end of the reasoning steps (between steps 45 and 55).
* Qwen-3-8B and GPT-OSS-20B show similar trends, with relatively low and stable similarity scores.
### Interpretation
The chart suggests that all the evaluated language models initially lose similarity as they progress through reasoning steps. This could indicate that the models diverge from their initial state as they engage in more complex thought processes. However, the models differ in how they maintain or recover similarity.
Claude-3.7-Sonnet's stability suggests it is more robust in maintaining a consistent internal representation during reasoning. Magistral-Small's consistently low scores might indicate a weaker ability to maintain coherence or relevance during reasoning. The increase in similarity for DS-R1-Qwen-7B towards the end could suggest that it converges on a solution or a more stable state after an initial period of exploration.
The metric "Similarity(Cτ, t)" likely represents a measure of how closely the model's internal state at reasoning step *t* aligns with some target condition *Cτ*. The rapid initial drop suggests that the models quickly move away from their initial state, while the subsequent behavior reveals their ability to maintain coherence or converge on a solution. The differences between the models highlight their varying strengths and weaknesses in reasoning tasks.