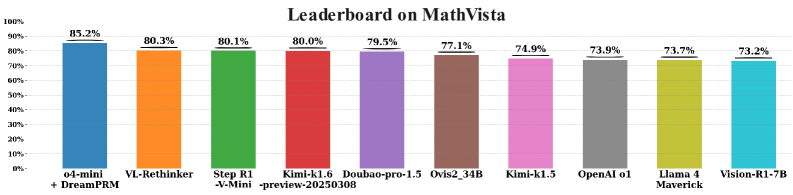
## Bar Chart: Leaderboard on MathVista
### Overview
The image is a horizontal bar chart displaying the performance scores of various AI models on the "MathVista" benchmark. The chart ranks models from highest to lowest score, with each model represented by a distinct colored bar. The title "Leaderboard on MathVista" is centered at the top.
### Components/Axes
* **Chart Title:** "Leaderboard on MathVista" (centered, top).
* **Y-Axis (Vertical):** Represents the performance score as a percentage. The axis is labeled with markers at 0%, 20%, 40%, 60%, 80%, and 100%.
* **X-Axis (Horizontal):** Lists the names of the AI models being compared. The labels are positioned below each corresponding bar.
* **Data Labels:** Each bar has its exact percentage score displayed directly above it.
* **Legend/Color Mapping:** Each model is assigned a unique color for its bar. The mapping is as follows (from left to right):
* Blue: `o4-mini + DreamPRM`
* Orange: `VL-Rethinker`
* Green: `Step R1-V-Mini-preview-20250308`
* Red: `Kimi-k1.6-preview-20250308`
* Purple: `Doubao-pro-1.5`
* Brown: `Ovis2_34B`
* Pink: `Kimi-k1.5`
* Grey: `OpenAI o1`
* Yellow-Green: `Llama 4 Maverick`
* Cyan: `Vision-R1-7B`
### Detailed Analysis
The chart presents a ranked list of 10 AI models based on their MathVista benchmark scores. The data is sorted in descending order of performance.
1. **o4-mini + DreamPRM** (Blue bar, far left): **85.2%**. This is the highest-performing model on the chart.
2. **VL-Rethinker** (Orange bar): **80.3%**.
3. **Step R1-V-Mini-preview-20250308** (Green bar): **80.1%**.
4. **Kimi-k1.6-preview-20250308** (Red bar): **80.0%**.
5. **Doubao-pro-1.5** (Purple bar): **79.5%**.
6. **Ovis2_34B** (Brown bar): **77.1%**.
7. **Kimi-k1.5** (Pink bar): **74.9%**.
8. **OpenAI o1** (Grey bar): **73.9%**.
9. **Llama 4 Maverick** (Yellow-Green bar): **73.7%**.
10. **Vision-R1-7B** (Cyan bar, far right): **73.2%**. This is the lowest-performing model shown.
**Trend Verification:** The visual trend is a clear, steady decline in bar height from left to right, corresponding to the descending order of the numerical scores. There are no sudden jumps or outliers that break this descending pattern.
### Key Observations
* **Performance Cluster:** The top four models (`o4-mini + DreamPRM`, `VL-Rethinker`, `Step R1-V-Mini`, `Kimi-k1.6`) form a leading cluster, all scoring at or above 80.0%. The gap between the 1st and 4th place is only 5.2 percentage points.
* **Significant Drop:** There is a noticeable performance drop of 2.4 percentage points between the 5th place model (`Doubao-pro-1.5` at 79.5%) and the 6th place model (`Ovis2_34B` at 77.1%).
* **Tight Grouping at the Lower End:** The bottom three models (`OpenAI o1`, `Llama 4 Maverick`, `Vision-R1-7B`) are very closely grouped, with only a 0.7 percentage point spread between them (73.9% to 73.2%).
* **Model Naming Conventions:** Several model names include version numbers or date stamps (e.g., `-preview-20250308`, `-1.5`, `_34B`), indicating they are likely specific releases or configurations.
### Interpretation
This leaderboard provides a snapshot of the competitive landscape for AI models on the MathVista benchmark, which evaluates mathematical and visual reasoning capabilities.
* **State of the Art:** The `o4-mini + DreamPRM` combination demonstrates a clear lead, suggesting that its specific architecture or training methodology (potentially involving a "DreamPRM" component) is currently highly effective for this type of task.
* **Competitive Middle Tier:** The tight clustering of models between 73% and 80% indicates a highly competitive field where incremental improvements can significantly change ranking. The presence of multiple models from similar families (e.g., two "Kimi" variants) shows iterative development within organizations.
* **Benchmark Context:** The scores, ranging from 73.2% to 85.2%, suggest that MathVista is a challenging benchmark where even top models do not achieve near-perfect scores. This implies the tasks involve complex reasoning that remains difficult for current AI systems.
* **Actionable Insight:** For researchers or users, this chart highlights which models are currently top performers for mathematical visual reasoning. The close scores among many models suggest that factors beyond raw accuracy—such as computational efficiency, speed, or specific sub-task performance—may be important for practical selection. The date stamps in some names also emphasize the rapid pace of development in this field.