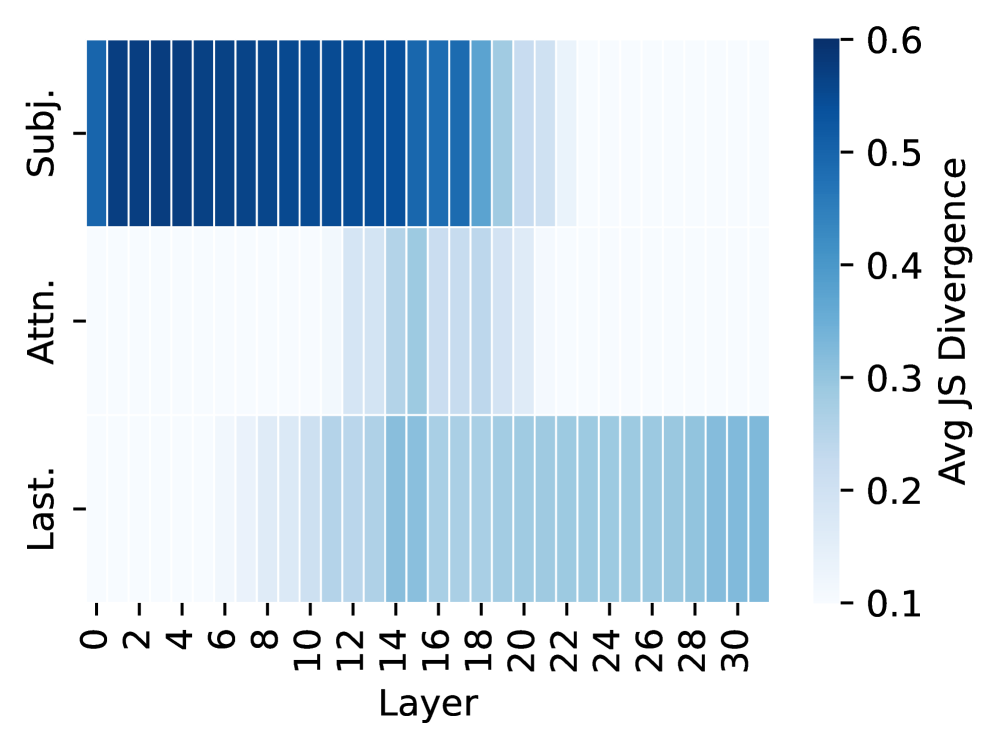
## Heatmap: Average JS Divergence Across Layers and Categories
### Overview
The image is a heatmap visualizing the average JS divergence values across three categories ("Subj.", "Attn.", "Last.") and 31 layers (0–30). The color intensity represents divergence magnitude, with darker blues indicating higher values (up to 0.6) and lighter blues/whites indicating lower values (down to 0.1).
### Components/Axes
- **Y-Axis (Categories)**:
- "Subj." (Subject)
- "Attn." (Attention)
- "Last." (Last)
- **X-Axis (Layers)**:
- Layer indices from 0 to 30 (inclusive).
- **Color Legend**:
- Positioned on the right, labeled "Avg JS Divergence."
- Gradient from light blue (0.1) to dark blue (0.6).
### Detailed Analysis
1. **Subject (Subj.)**:
- Dark blue bars dominate the top section.
- Values start near 0.6 at Layer 0 and gradually decrease to ~0.4 by Layer 30.
- Consistent high divergence across all layers.
2. **Attention (Attn.)**:
- Middle section with lighter blue shades.
- Values start near 0.3 at Layer 0 and decrease to ~0.15 by Layer 30.
- Moderate divergence, lower than Subject but higher than Last.
3. **Last (Last.)**:
- Bottom section with the lightest blue/white shades.
- Values start near 0.1 at Layer 0 and decrease to ~0.05 by Layer 30.
- Lowest divergence across all layers.
### Key Observations
- **Trend**: All categories show a **decreasing divergence trend** as layer indices increase.
- **Dominance**: "Subj." consistently exhibits the highest divergence, followed by "Attn." and "Last."
- **Layer Sensitivity**: Early layers (0–10) show the strongest divergence for all categories, with values dropping sharply in later layers (20–30).
### Interpretation
The data suggests that **Subject features** are the most distinct and discriminative across all layers, likely due to their role in encoding specific information. **Attention features** show moderate divergence, indicating their importance in modulating focus but with less specificity than Subject features. **Last features** exhibit the lowest divergence, implying they may represent more generalized or abstracted information. The uniform decrease in divergence with increasing layers across all categories suggests that higher layers prioritize integration or abstraction over fine-grained distinctions. This pattern aligns with typical neural network behavior, where early layers capture raw features and later layers synthesize higher-level representations.