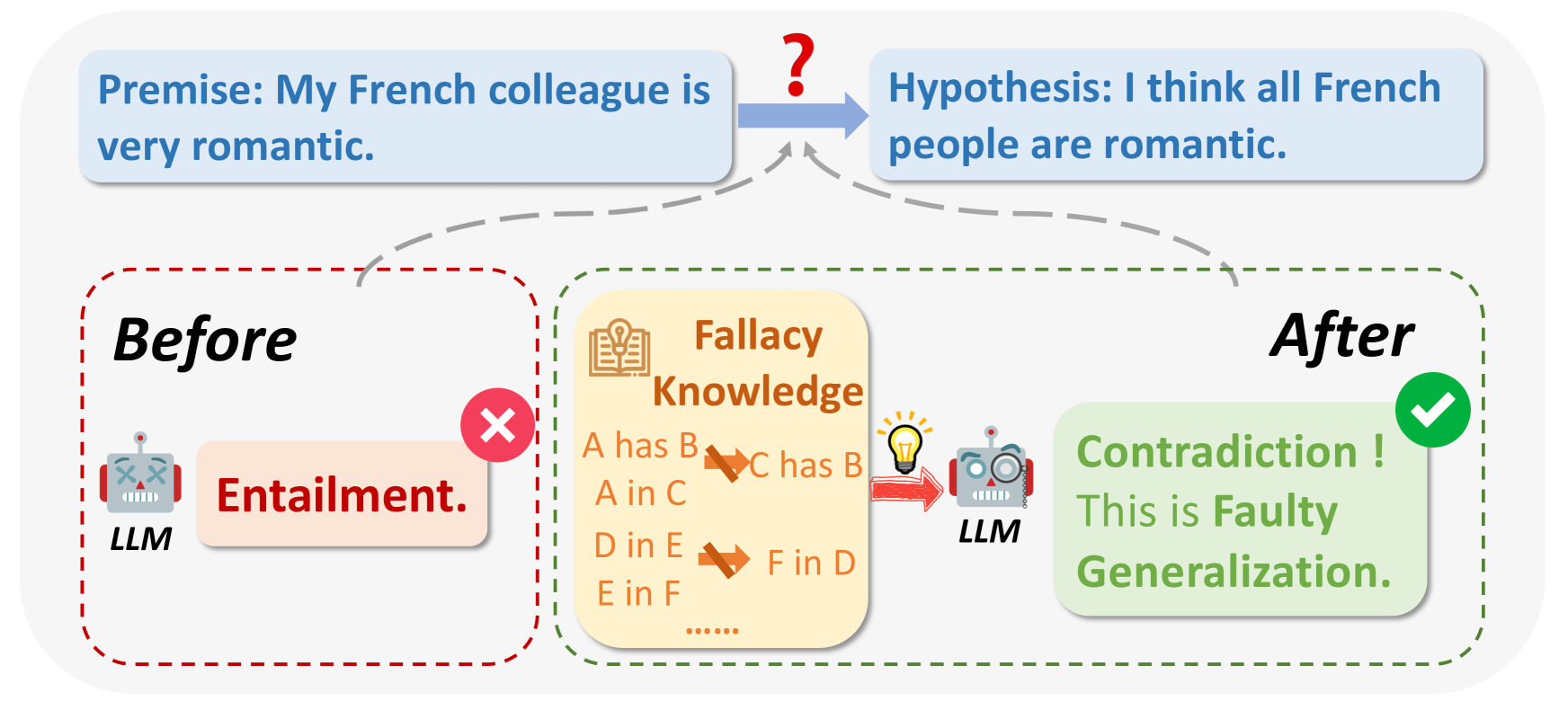
## Diagram: Fallacy Detection by LLM
### Overview
The diagram illustrates how a Large Language Model (LLM) can identify a fallacy in reasoning. It shows the transformation of a premise into a hypothesis and the LLM's role in detecting a faulty generalization. The diagram is divided into "Before" and "After" states, highlighting the LLM's intervention.
### Components/Axes
* **Top:**
* **Premise:** "My French colleague is very romantic." (Contained in a light blue rounded rectangle)
* **Arrow:** A blue arrow with a question mark above it, pointing from the premise to the hypothesis.
* **Hypothesis:** "I think all French people are romantic." (Contained in a light blue rounded rectangle)
* **Bottom-Left ("Before"):**
* **Label:** "Before" (Bold text)
* **LLM (Robot):** A cartoon robot labeled "LLM"
* **Entailment:** A light pink rounded rectangle containing the word "Entailment."
* **Red X:** A red "X" mark above the "Entailment" box.
* **Red Dashed Border:** A red dashed line surrounds the "Before" section.
* **Center:**
* **Fallacy Knowledge:** A light yellow rounded rectangle labeled "Fallacy Knowledge" with a book and lightbulb icon.
* **Fallacy Rules:**
* "A has B -> C has B"
* "A in C"
* "D in E -> F in D"
* "E in F"
* "......"
* **Bottom-Right ("After"):**
* **Label:** "After" (Bold text)
* **LLM (Robot):** A cartoon robot labeled "LLM" with a magnifying glass.
* **Contradiction! This is Faulty Generalization.:** A light green rounded rectangle containing the text "Contradiction! This is Faulty Generalization."
* **Green Checkmark:** A green checkmark above the "Contradiction!" box.
* **Green Dashed Border:** A green dashed line surrounds the "After" section.
* **Arrows:**
* A red arrow points from the "Fallacy Knowledge" box to the "LLM" in the "After" section.
* Grey dashed lines connect the "Before" and "After" sections to the premise and hypothesis.
### Detailed Analysis
* **Premise to Hypothesis:** The premise "My French colleague is very romantic" is transformed into the hypothesis "I think all French people are romantic." This transformation is indicated by a blue arrow with a question mark, suggesting a potential logical leap or inference.
* **Before State:** Initially, the LLM incorrectly identifies the premise as entailing the hypothesis, indicated by the "Entailment" label and the red "X" mark.
* **Fallacy Knowledge:** The "Fallacy Knowledge" box contains general rules or patterns of fallacious reasoning. The rules are represented as "A has B -> C has B", "A in C", "D in E -> F in D", and "E in F". The "......" suggests that there are more rules not explicitly listed.
* **After State:** After applying its "Fallacy Knowledge," the LLM correctly identifies the hypothesis as a "Contradiction!" and a "Faulty Generalization," indicated by the green checkmark. The LLM in the "After" state has a magnifying glass, suggesting it is analyzing the information.
### Key Observations
* The diagram highlights the LLM's ability to evolve its understanding of a statement from an initial incorrect assessment ("Entailment") to a correct identification of a fallacy ("Contradiction! This is Faulty Generalization.").
* The "Fallacy Knowledge" box is crucial, as it provides the LLM with the necessary rules to detect logical fallacies.
* The use of visual cues (red "X" and green checkmark) clearly indicates the LLM's initial error and subsequent correction.
### Interpretation
The diagram demonstrates how an LLM can be used to identify and correct faulty reasoning. The LLM initially makes an incorrect assessment, but by applying its "Fallacy Knowledge," it can identify the logical fallacy and correct its assessment. This suggests that LLMs can be valuable tools for improving the quality of reasoning and decision-making. The diagram illustrates the importance of equipping LLMs with knowledge of common fallacies to improve their reasoning capabilities. The transformation from "Entailment" to "Contradiction!" shows the LLM's ability to learn and adapt its understanding based on new information.