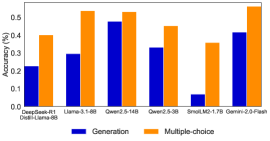
## Bar Chart: Model Accuracy Comparison (Generation vs Multiple-choice)
### Overview
The chart compares the accuracy of two methods—Generation and Multiple-choice—across six AI models: DeepSeek-R1, Llama-3-1-8B, Qwen2.5-14B, Qwen2.5-3B, SmolLM2-1.7B, and Gemini-2.0-Flash. Accuracy is measured in percentage, with values ranging from 0.0% to 0.6%.
### Components/Axes
- **X-axis**: Model names (DeepSeek-R1, Llama-3-1-8B, Qwen2.5-14B, Qwen2.5-3B, SmolLM2-1.7B, Gemini-2.0-Flash).
- **Y-axis**: Accuracy (%) from 0.0 to 0.6 in increments of 0.1.
- **Legend**:
- Blue bars = Generation
- Orange bars = Multiple-choice
- **Title**: Not explicitly visible in the image.
### Detailed Analysis
1. **DeepSeek-R1**:
- Generation: ~0.23% (blue)
- Multiple-choice: ~0.40% (orange)
2. **Llama-3-1-8B**:
- Generation: ~0.30% (blue)
- Multiple-choice: ~0.54% (orange)
3. **Qwen2.5-14B**:
- Generation: ~0.48% (blue)
- Multiple-choice: ~0.53% (orange)
4. **Qwen2.5-3B**:
- Generation: ~0.33% (blue)
- Multiple-choice: ~0.45% (orange)
5. **SmolLM2-1.7B**:
- Generation: ~0.07% (blue)
- Multiple-choice: ~0.36% (orange)
6. **Gemini-2.0-Flash**:
- Generation: ~0.42% (blue)
- Multiple-choice: ~0.57% (orange)
### Key Observations
- **Trend Verification**:
- Multiple-choice consistently outperforms Generation across all models.
- The largest gap occurs in SmolLM2-1.7B (Generation: ~0.07%, Multiple-choice: ~0.36%).
- Gemini-2.0-Flash shows the highest accuracy for both methods (~0.42% Generation, ~0.57% Multiple-choice).
- **Outliers**:
- SmolLM2-1.7B has the lowest Generation accuracy (~0.07%), significantly lower than other models.
- Qwen2.5-14B has the highest Generation accuracy (~0.48%) but a smaller gap compared to Multiple-choice (~0.53%).
### Interpretation
The data suggests that **Multiple-choice methods generally achieve higher accuracy than Generation** across diverse AI models. This could indicate that Multiple-choice frameworks are more robust or better aligned with evaluation criteria. However, the stark underperformance of Generation in SmolLM2-1.7B raises questions about model-specific limitations or training data quality. Gemini-2.0-Flash emerges as the strongest performer overall, suggesting advanced architecture or optimization. The results highlight the need for method-specific optimizations, particularly for smaller models like SmolLM2-1.7B.