\n
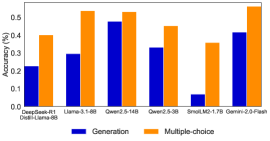
## Bar Chart: Model Accuracy Comparison
### Overview
This bar chart compares the accuracy of several language models on two different task types: "Generation" and "Multiple-choice". The accuracy is measured as a percentage, ranging from 0.0 to 0.6. The models being compared are DeepSeek-RL1, Llama-2-6B, Gwer2.5-14B, Gwer2.5-3B, SmalM2-1.7B, and Gemini-2.0-Flash.
### Components/Axes
* **X-axis:** Model Names - DeepSeek-RL1, Llama-2-6B, Gwer2.5-14B, Gwer2.5-3B, SmalM2-1.7B, Gemini-2.0-Flash.
* **Y-axis:** Accuracy (%) - Scale ranges from 0.0 to 0.6, with increments of 0.1.
* **Legend:**
* Blue bars: "Generation"
* Orange bars: "Multiple-choice"
* **Positioning:** The legend is located at the bottom-center of the chart.
### Detailed Analysis
The chart consists of paired bars for each model, representing its performance on the "Generation" and "Multiple-choice" tasks.
* **DeepSeek-RL1:** Generation accuracy is approximately 0.24. Multiple-choice accuracy is approximately 0.39.
* **Llama-2-6B:** Generation accuracy is approximately 0.29. Multiple-choice accuracy is approximately 0.54.
* **Gwer2.5-14B:** Generation accuracy is approximately 0.46. Multiple-choice accuracy is approximately 0.55.
* **Gwer2.5-3B:** Generation accuracy is approximately 0.32. Multiple-choice accuracy is approximately 0.44.
* **SmalM2-1.7B:** Generation accuracy is approximately 0.08. Multiple-choice accuracy is approximately 0.34.
* **Gemini-2.0-Flash:** Generation accuracy is approximately 0.40. Multiple-choice accuracy is approximately 0.57.
**Trends:**
* For most models, the "Multiple-choice" accuracy is higher than the "Generation" accuracy.
* Gwer2.5-14B shows the highest "Generation" accuracy.
* Gemini-2.0-Flash shows the highest "Multiple-choice" accuracy.
* SmalM2-1.7B shows the lowest "Generation" accuracy.
### Key Observations
* There's a clear performance difference between models, with some consistently outperforming others on both tasks.
* The gap between "Generation" and "Multiple-choice" accuracy varies significantly across models.
* Gwer2.5-14B is a strong performer in the "Generation" task, while Gemini-2.0-Flash excels in "Multiple-choice".
* SmalM2-1.7B is a clear outlier with very low "Generation" accuracy.
### Interpretation
The data suggests that the choice of model significantly impacts performance on both generation and multiple-choice tasks. The higher accuracy scores for "Multiple-choice" across most models indicate that these models are generally better at selecting the correct answer from a given set of options than they are at generating novel responses. The substantial difference in performance between SmalM2-1.7B and the other models suggests that model size or architecture plays a crucial role in generation capabilities. The strong performance of Gwer2.5-14B in generation and Gemini-2.0-Flash in multiple-choice suggests that different models may be optimized for different types of tasks. This information is valuable for selecting the most appropriate model for a specific application. The chart highlights the trade-offs between different models and the importance of considering the task type when evaluating model performance.