## Bar Chart: Model Accuracy Comparison (Generation vs. Multiple-choice)
### Overview
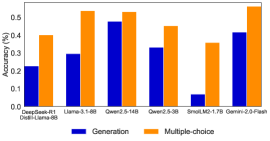
The image is a vertical bar chart comparing the accuracy of seven different large language models on two distinct task types: "Generation" and "Multiple-choice." The chart visually demonstrates a consistent performance gap between the two evaluation methods across all models shown.
### Components/Axes
* **Chart Type:** Grouped bar chart.
* **X-axis (Horizontal):** Lists seven model names. From left to right:
1. DeepSeek-V3
2. Llama-3.1-405B
3. Qwen2-110B
4. Qwen2-72B
5. SmolLM2-1.7B
6. Llama-3.1-70B
7. Qwen2-7B-Plain
* **Y-axis (Vertical):** Labeled "Accuracy (%)". The scale runs from 0 to 0.5 (representing 0% to 50%), with major tick marks at 0.1 intervals (0.1, 0.2, 0.3, 0.4, 0.5).
* **Legend:** Located in the top-right corner of the chart area.
* A blue square corresponds to the label "Generation".
* An orange square corresponds to the label "Multiple-choice".
* **Data Series:** Two series of bars are plotted for each model on the x-axis.
* **Blue Bars (Left):** Represent "Generation" accuracy.
* **Orange Bars (Right):** Represent "Multiple-choice" accuracy.
### Detailed Analysis
For each model, the "Multiple-choice" (orange) bar is significantly taller than the "Generation" (blue) bar. Approximate accuracy values, estimated from the bar heights relative to the y-axis, are as follows:
| Model Name | Generation Accuracy (Blue, Approx.) | Multiple-choice Accuracy (Orange, Approx.) |
| :--- | :--- | :--- |
| DeepSeek-V3 | ~0.28 (28%) | ~0.38 (38%) |
| Llama-3.1-405B | ~0.30 (30%) | ~0.50 (50%) |
| Qwen2-110B | ~0.48 (48%) | ~0.50 (50%) |
| Qwen2-72B | ~0.32 (32%) | ~0.42 (42%) |
| SmolLM2-1.7B | ~0.05 (5%) | ~0.35 (35%) |
| Llama-3.1-70B | ~0.08 (8%) | ~0.35 (35%) |
| Qwen2-7B-Plain | ~0.42 (42%) | ~0.50 (50%) |
**Trend Verification:**
* **Generation Series (Blue):** The trend is highly variable. It starts moderate (~28%), rises to a peak with Qwen2-110B (~48%), then drops sharply for SmolLM2-1.7B and Llama-3.1-70B (both below 10%), before rising again for Qwen2-7B-Plain (~42%).
* **Multiple-choice Series (Orange):** The trend is more stable and consistently high. All models achieve between ~35% and ~50% accuracy. The lowest values are for SmolLM2-1.7B and Llama-3.1-70B (~35%), while three models (Llama-3.1-405B, Qwen2-110B, Qwen2-7B-Plain) reach or approach the 50% mark.
### Key Observations
1. **Universal Performance Gap:** Every single model performs substantially better on the "Multiple-choice" task than on the "Generation" task. The gap is often 20 percentage points or more.
2. **Outlier in Generation Performance:** The "SmolLM2-1.7B" model shows an extremely low "Generation" accuracy (~5%), which is a dramatic outlier compared to its "Multiple-choice" performance (~35%) and the generation scores of other models.
3. **Top Performers:** "Qwen2-110B" and "Qwen2-7B-Plain" show the strongest combined performance, with high scores in both categories, though multiple-choice remains superior.
4. **Scale vs. Performance:** There is no clear, linear correlation between model size (as implied by the names, e.g., 405B vs. 1.7B) and accuracy in this chart. For example, the largest model (Llama-3.1-405B) does not have the highest generation score, and a smaller model (Qwen2-7B-Plain) outperforms several larger ones in generation.
### Interpretation
This chart provides a clear, data-driven insight into a fundamental challenge in evaluating large language models. The consistent and large disparity between "Multiple-choice" and "Generation" accuracy suggests that **the format of the evaluation task dramatically influences the measured performance of a model.**
* **What the data suggests:** Models are significantly more proficient at selecting a correct answer from a predefined set (multiple-choice) than they are at generating a correct answer from scratch (generation). This implies that the cognitive or computational load of open-ended generation is much higher, or that models are better optimized for recognition-based tasks than creation-based ones.
* **How elements relate:** The side-by-side bars for each model force a direct comparison, highlighting that the task type is a more dominant factor in the accuracy score than the specific model architecture or size in this particular evaluation.
* **Notable implications:** This has critical implications for AI benchmarking. If a model's capability is primarily reported using multiple-choice benchmarks, it may present an overly optimistic view of its ability to perform real-world tasks that require generating novel text, code, or solutions. The outlier performance of SmolLM2-1.7B in generation could indicate a specific weakness in that model's training or architecture for generative tasks, despite having reasonable recognition abilities. The chart argues for the necessity of using diverse evaluation methodologies to build a complete picture of a model's capabilities.