\n
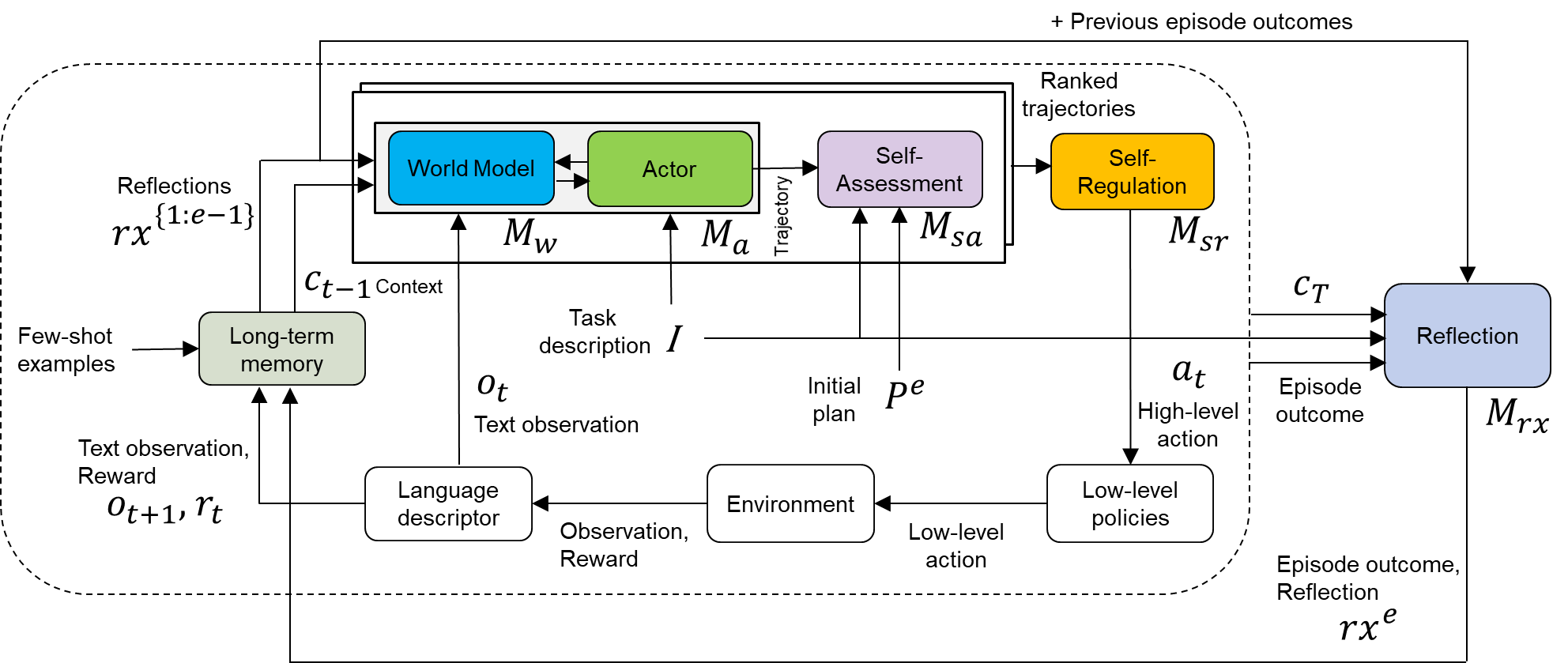
## Diagram: Reflexion Architecture
### Overview
The image depicts a diagram of a Reflexion architecture, a framework for agents that iteratively improve their performance through self-reflection. The diagram illustrates the flow of information between various components, including a World Model, Actor, Self-Assessment, Self-Regulation, Environment, and Long-term Memory. The diagram is segmented into a main loop with inputs and outputs, and a reflection loop.
### Components/Axes
The diagram consists of the following components:
* **World Model (Blue):** Labeled as *M<sub>W</sub>*. Receives context *c<sub>t-1</sub>*.
* **Actor (Red):** Labeled as *M<sub>α</sub>*. Receives context *c<sub>t-1</sub>* and Task description *I*. Outputs trajectory.
* **Self-Assessment (Yellow):** Labeled as *M<sub>sa</sub>*. Receives trajectory from the Actor.
* **Self-Regulation (Green):** Labeled as *M<sub>sr</sub>*. Receives output from Self-Assessment. Outputs context *c<sub>T</sub>*.
* **Environment (Gray):** Receives initial plan *p<sub>e</sub>* and low-level action. Outputs Observation and Reward.
* **Long-term Memory (Light Gray):** Receives Text observation and Reward *r<sub>t</sub>*. Outputs few-shot examples.
* **Language Descriptor (Light Gray):** Receives Text observation and Reward *r<sub>t</sub>*.
* **Reflection (Purple):** Labeled as *M<sub>rx</sub>*. Receives Episode outcome. Outputs Reflections *rx<sup>{1e-13}</sup>*.
* **Inputs:** Few-shot examples, Task description *I*, Text observation *o<sub>t</sub>*, Reward *r<sub>t</sub>*, Previous episode outcomes.
* **Outputs:** High-level action *a<sub>t</sub>*, Episode outcome, Reflection *rx<sup>e</sup>*.
The diagram also includes labels for data flow:
* Context: *c<sub>t-1</sub>*, *c<sub>T</sub>*
* Initial plan: *p<sub>e</sub>*
* Reflections: *rx<sup>{1e-13}</sup>*, *rx<sup>e</sup>*
* Trajectory
* Observation, Reward
### Detailed Analysis
The diagram illustrates a cyclical process.
1. **Context Input:** The process begins with context *c<sub>t-1</sub>* being fed into both the World Model and the Actor.
2. **Task & Actor:** The Actor also receives a Task description *I*. The Actor generates a trajectory.
3. **Self-Assessment & Regulation:** The trajectory is passed to the Self-Assessment module, which then passes its output to the Self-Regulation module.
4. **Context Update:** The Self-Regulation module outputs updated context *c<sub>T</sub>*.
5. **Environment Interaction:** The Actor generates an initial plan *p<sub>e</sub>* and a low-level action that is sent to the Environment.
6. **Feedback Loop:** The Environment returns an Observation and Reward.
7. **Memory Update:** The Observation and Reward are fed into the Language Descriptor and Long-term Memory.
8. **Reflection Loop:** The Episode outcome is sent to the Reflection module, which outputs Reflections *rx<sup>e</sup>*. These reflections are then used to update the initial context *c<sub>t-1</sub>* via *rx<sup>{1e-13}</sup>*.
9. **Previous Episode Outcomes:** The diagram also shows that previous episode outcomes feed into the Self-Regulation module.
The diagram uses arrows to indicate the direction of information flow. The dashed arrows represent feedback loops or external inputs. The colors of the components are consistent throughout the diagram.
### Key Observations
The diagram highlights the importance of self-reflection in the Reflexion architecture. The reflection loop allows the agent to learn from its past experiences and improve its performance over time. The use of separate modules for World Modeling, Acting, Self-Assessment, and Self-Regulation suggests a modular and potentially scalable design. The inclusion of Long-term Memory and Few-shot examples indicates the agent can leverage prior knowledge and adapt to new tasks.
### Interpretation
The diagram represents a sophisticated agent architecture designed for iterative improvement through self-reflection. The core idea is that by analyzing its own actions and outcomes, the agent can refine its internal models and strategies, leading to better performance. The separation of concerns into distinct modules (World Model, Actor, etc.) promotes modularity and allows for independent development and optimization of each component. The feedback loops, particularly the reflection loop, are crucial for enabling continuous learning and adaptation. The diagram suggests a system capable of not just performing tasks, but also understanding *why* it succeeds or fails, and using that understanding to improve its future behavior. The use of a language descriptor and long-term memory suggests the agent can leverage natural language processing and store/retrieve relevant experiences for future use. The notation *rx<sup>{1e-13}</sup>* likely represents a very small weighting factor applied to the reflections, indicating that past reflections have a subtle but persistent influence on the agent's current context.