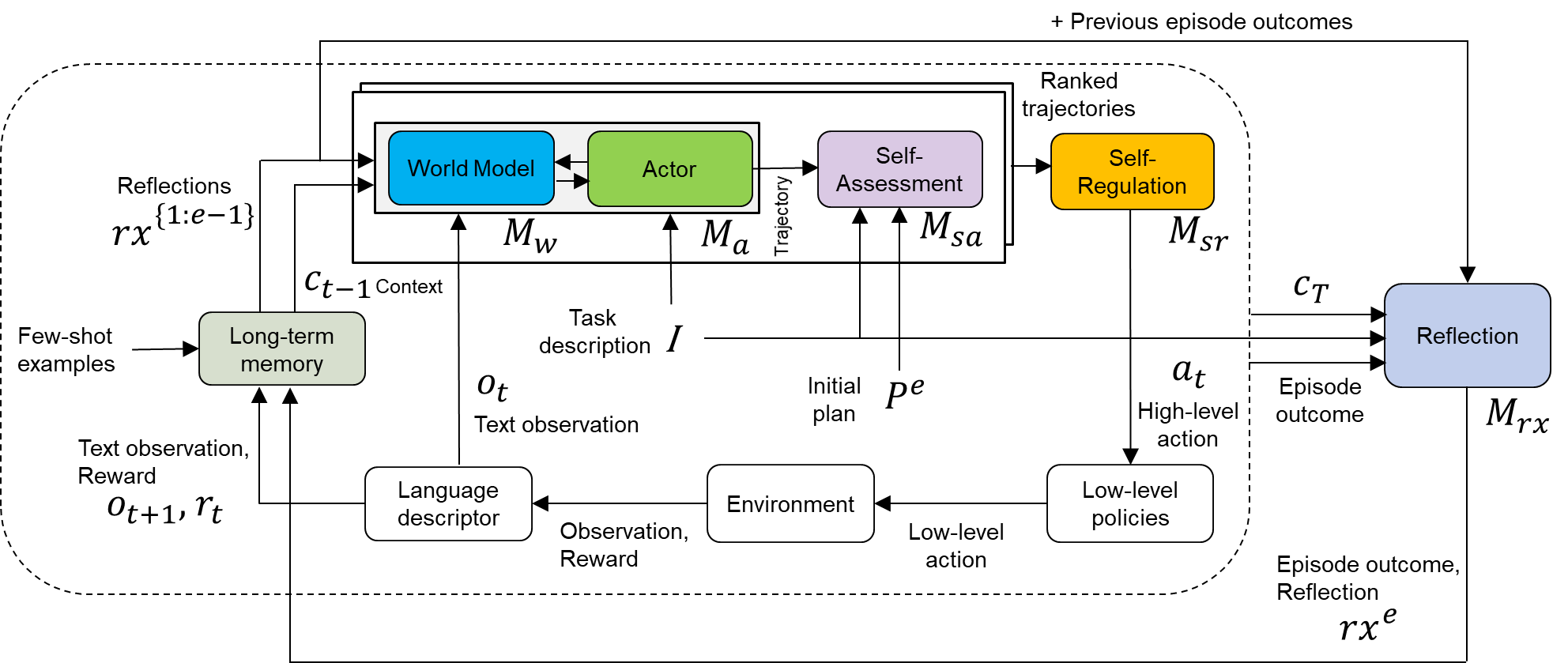
## Diagram: Adaptive Learning System Architecture
### Overview
The diagram illustrates a hierarchical adaptive learning system integrating world modeling, decision-making, and self-regulation. It features feedback loops, memory components, and environmental interaction, with explicit connections between high-level planning and low-level execution.
### Components/Axes
1. **Core Modules**:
- **World Model** (Blue): Processes task descriptions and initial plans
- **Actor** (Green): Executes high-level actions
- **Self-Assessment** (Purple): Evaluates trajectories
- **Self-Regulation** (Yellow): Adjusts strategies based on assessments
2. **Memory & Context**:
- **Long-term memory** (Light Green): Stores few-shot examples
- **Reflections** (Light Blue): Processes episode outcomes
- **Context** (Cₜ₋₁): Maintains historical context
3. **Environment Interaction**:
- **Environment**: Provides observations and rewards
- **Low-level policies**: Execute specific actions
4. **Flow Elements**:
- **Task description** (I): Input to World Model
- **Initial plan** (pₑ): Output from World Model
- **High-level action** (aₜ): Output from Actor
- **Low-level action**: Output from policies
5. **Feedback Loops**:
- **Reflections** → **Self-Regulation** → **World Model**
- **Episode outcome** → **Reflections**
### Detailed Analysis
- **World Model** (Mₐ) receives task descriptions (I) and initial plans (pₑ), integrating context (Cₜ₋₁) and few-shot examples
- **Actor** (Mₐ) generates high-level actions (aₜ) based on world model outputs
- **Self-Assessment** (Mₛₐ) evaluates trajectories using ranked trajectories from previous episodes
- **Self-Regulation** (Mₛᵣ) adjusts strategies based on assessments (Mₛₐ)
- **Environment** provides text observations (oₜ) and rewards (rₜ), which feed into language descriptor and low-level policies
- **Reflections** (Mᵣˣ) process episode outcomes (rxᵉ) and previous reflections (rx¹ˢ¹), creating updated context (Cₜ)
### Key Observations
1. **Hierarchical Structure**: Clear separation between strategic (World Model/Actor) and operational (policies) components
2. **Memory Integration**: Long-term memory and reflections create temporal continuity
3. **Feedback Density**: Multiple feedback loops (4 explicit) enable continuous adaptation
4. **Modularity**: Components operate semi-independently but with defined interfaces
5. **Temporal Processing**: Explicit handling of current (oₜ₊₁) and previous (Cₜ₋₁) context
### Interpretation
This architecture demonstrates a sophisticated closed-loop system where:
- **Strategic planning** (World Model) informs **tactical execution** (Actor)
- **Performance evaluation** (Self-Assessment) drives **adaptive refinement** (Self-Regulation)
- **Environmental feedback** grounds decisions in real-world outcomes
- **Memory systems** prevent catastrophic forgetting while enabling generalization
The system appears designed for complex, dynamic environments requiring both immediate responsiveness (low-level policies) and long-term strategic adaptation (world model). The explicit ranking of trajectories suggests a preference for exploring high-performing strategies while maintaining exploration through few-shot examples. The reflection component's integration of both current outcomes and historical reflections indicates a meta-cognitive approach to learning.