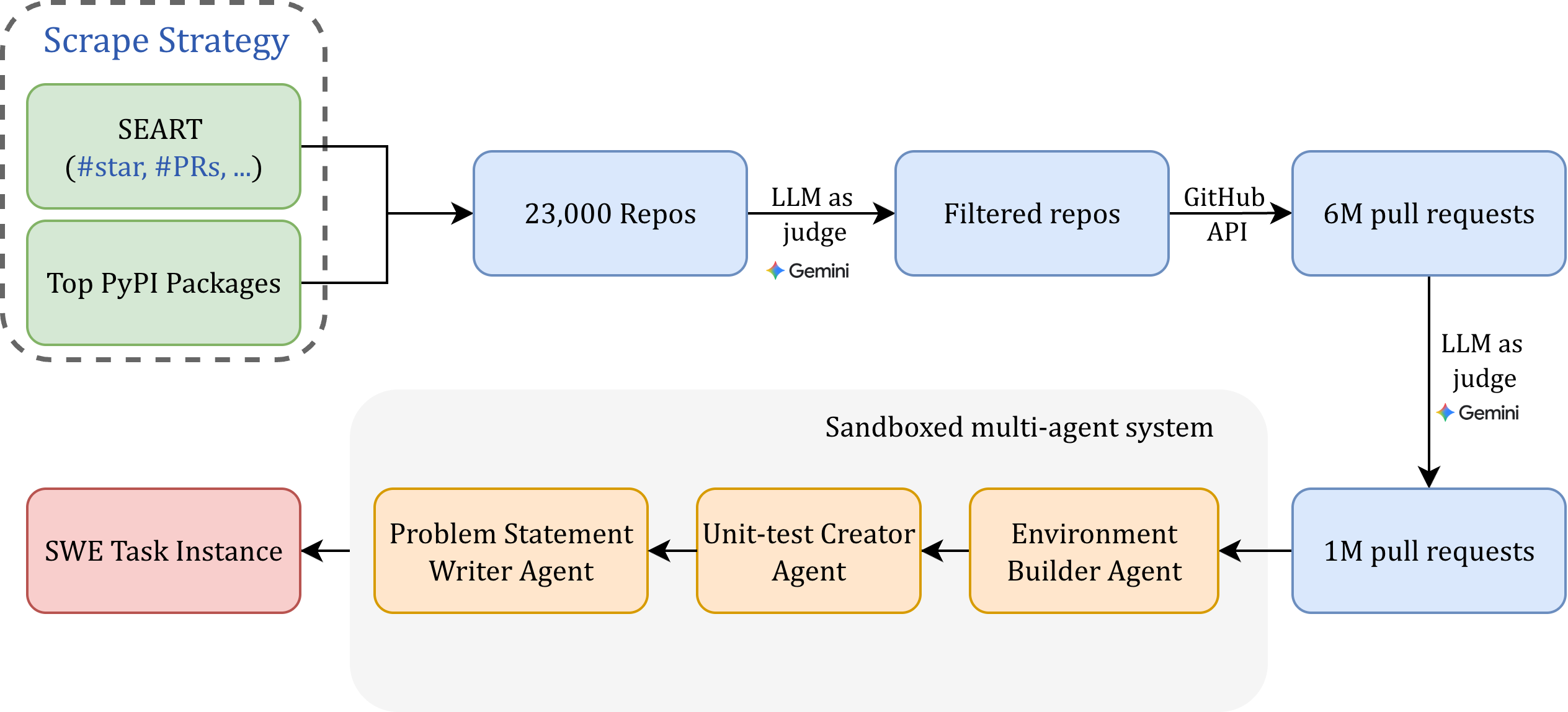
## Flowchart: Software Development Evaluation Pipeline
### Overview
The diagram illustrates a multi-stage pipeline for evaluating software repositories and pull requests using a combination of automated scraping, filtering, and sandboxed multi-agent systems. The process begins with data collection from public repositories and PyPI packages, followed by iterative filtering and evaluation through large language models (LLMs) and specialized agents.
### Components/Axes
1. **Scrape Strategy** (Top-left box):
- Contains two data sources:
- **SEART** (`#star`, `#PRs`, ...)
- **Top PyPI Packages**
- Output: **23,000 Repos** (blue box)
2. **Filtering Stage**:
- **LLM as Judge (Gemini)** filters **23,000 Repos** into **Filtered Repos** (blue box)
- **GitHub API** connects **Filtered Repos** to **6M Pull Requests** (blue box)
3. **Sandboxed Multi-Agent System** (Bottom section):
- **SWE Task Instance** (red box) feeds into:
- **Problem Statement Writer Agent** (orange box)
- **Unit-test Creator Agent** (orange box)
- **Environment Builder Agent** (orange box)
- Output: **1M Pull Requests** (blue box)
4. **Final Evaluation**:
- **LLM as Judge (Gemini)** evaluates **6M Pull Requests** and **1M Pull Requests** (blue box)
### Detailed Analysis
- **Data Flow**:
- Scrape Strategy → 23,000 Repos → Filtered Repos → 6M Pull Requests
- SWE Task Instance → Problem Statement Writer Agent → Unit-test Creator Agent → Environment Builder Agent → 1M Pull Requests
- **Key Nodes**:
- **LLM as Judge (Gemini)** appears twice, indicating its role in both repository filtering and pull request evaluation.
- **GitHub API** acts as a bridge between filtered repositories and pull request data.
- **Quantitative Values**:
- 23,000 repositories initially scraped
- 6 million pull requests processed via GitHub API
- 1 million pull requests processed through the sandboxed system
### Key Observations
1. **Scalability Challenges**:
- The pipeline handles massive datasets (23k → 6M → 1M), suggesting distributed computing or incremental processing.
2. **Automation**:
- Gemini LLM is used for both repository filtering and pull request evaluation, emphasizing automated quality control.
3. **Modular Design**:
- The sandboxed multi-agent system isolates specific tasks (problem statements, unit tests, environment building), enabling parallel processing.
4. **Reduction Ratio**:
- 23,000 repositories → 1M pull requests (43x reduction), highlighting aggressive filtering at multiple stages.
### Interpretation
This pipeline demonstrates a hybrid approach combining:
1. **Data Scraping**: Initial collection from public sources (SEART, PyPI)
2. **Automated Filtering**: LLM-based quality assessment to reduce noise
3. **Sandboxed Evaluation**: Isolated environments for safe code execution and testing
4. **Multi-Agent Collaboration**: Specialized agents handle distinct aspects of software evaluation
The use of Gemini as a judge in both stages suggests a focus on consistency in evaluation criteria. The 43x reduction ratio indicates that only ~2.2% of initial repositories survive the filtering process, implying stringent quality thresholds. The sandboxed system's contribution to 1M pull requests shows its critical role in handling complex evaluation tasks that require isolated environments.