\n
## Diagram: System Architecture for Software Testing
### Overview
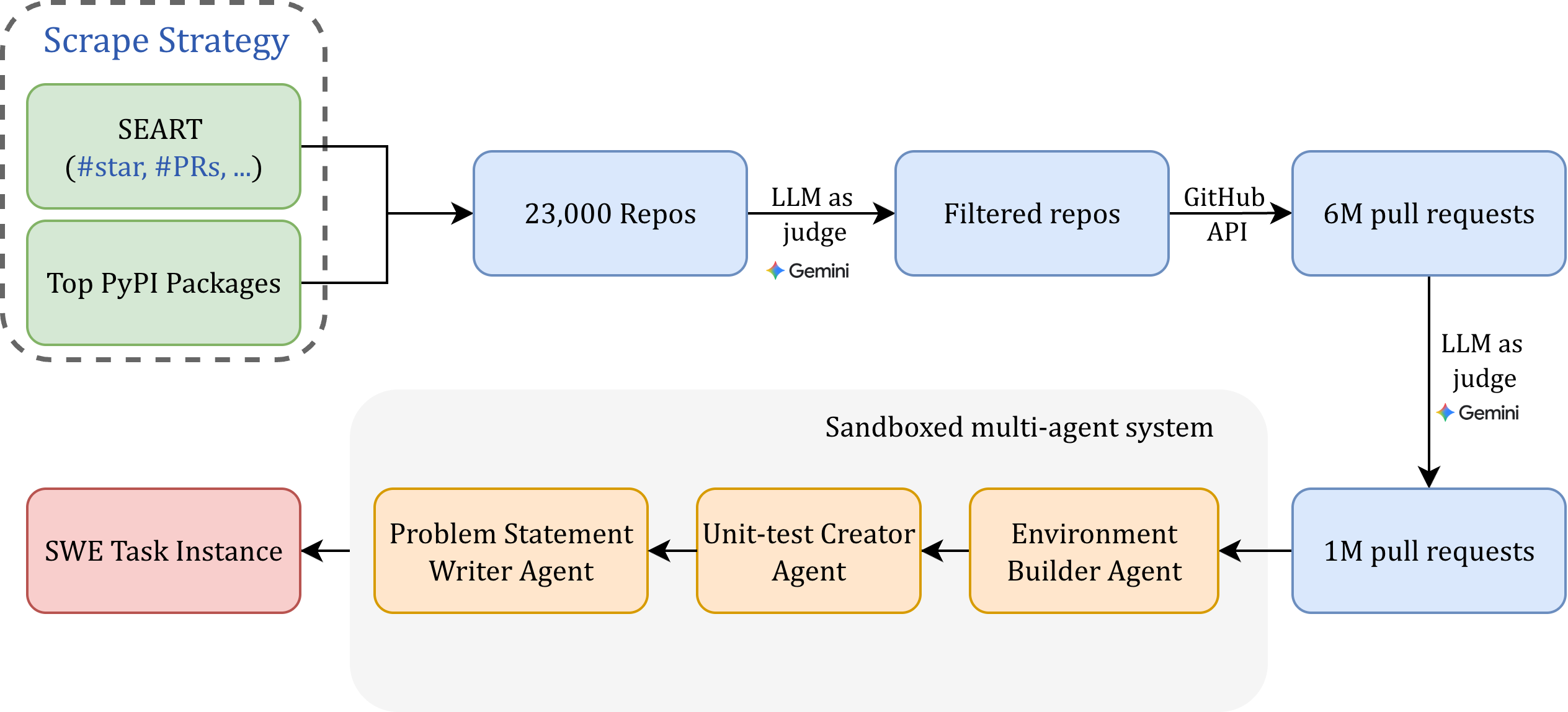
This diagram illustrates the architecture of a system designed for automated software testing, leveraging Large Language Models (LLMs) and GitHub APIs. The system begins with a scraping strategy, filters repositories, and then utilizes LLMs to judge and process pull requests, ultimately feeding into a sandboxed multi-agent system for task execution.
### Components/Axes
The diagram consists of several key components connected by arrows indicating data flow:
* **Scrape Strategy:** Includes "Top PyPI Packages" and "SEART (#star, #PRs, ...)"
* **23,000 Repos:** Represents the initial set of repositories obtained.
* **LLM as judge (Gemini):** An LLM, specifically Gemini, used for initial filtering and judgment.
* **Filtered repos:** The repositories that pass the LLM's initial judgment.
* **GitHub API:** Used to access and retrieve data from GitHub.
* **6M pull requests:** The number of pull requests retrieved from GitHub.
* **Sandboxed multi-agent system:** The core execution environment.
* **Problem Statement Writer Agent:** An agent responsible for formulating problem statements.
* **Unit-test Creator Agent:** An agent responsible for creating unit tests.
* **Environment Builder Agent:** An agent responsible for building the testing environment.
* **SWE Task Instance:** The final output or result of the system.
* **1M pull requests:** The number of pull requests processed within the sandboxed system.
* **LLM as judge (Gemini):** Another instance of the Gemini LLM used for judging within the sandboxed system.
### Detailed Analysis or Content Details
The diagram shows a clear flow of information:
1. The process starts with a "Scrape Strategy" that targets "Top PyPI Packages" and uses "SEART (#star, #PRs, ...)" as a search criteria.
2. This strategy results in the identification of "23,000 Repos".
3. These repositories are then passed to an "LLM as judge (Gemini)" which filters them, resulting in "Filtered repos".
4. The "Filtered repos" are accessed via the "GitHub API", yielding "6M pull requests".
5. These pull requests are then processed by another "LLM as judge (Gemini)", which filters them down to "1M pull requests".
6. The "1M pull requests" are fed into a "Sandboxed multi-agent system" consisting of three agents: "Problem Statement Writer Agent", "Unit-test Creator Agent", and "Environment Builder Agent".
7. These agents work in sequence: Problem Statement -> Unit-test Creation -> Environment Building.
8. The output of this system is a "SWE Task Instance".
### Key Observations
* The system utilizes LLMs (Gemini) at two distinct stages: initial repository filtering and pull request processing.
* There's a significant reduction in the number of pull requests processed (6M -> 1M), indicating a substantial filtering effect by the LLM.
* The sandboxed multi-agent system suggests a modular and potentially parallelized approach to software testing.
* The "SEART (#star, #PRs, ...)" component suggests that the scraping strategy considers the number of stars and pull requests as important metrics.
### Interpretation
This diagram depicts a sophisticated automated software testing pipeline. The use of LLMs for filtering suggests an attempt to prioritize relevant repositories and pull requests, reducing the computational burden on the downstream agents. The sandboxed multi-agent system allows for a division of labor, with each agent specializing in a specific aspect of the testing process. The reduction in pull requests from 6M to 1M indicates the LLM is effectively identifying and discarding irrelevant or low-quality contributions. The overall architecture suggests a focus on scalability and efficiency in automated software testing, leveraging the capabilities of LLMs and the vast resources available on GitHub. The system appears to be designed to automatically generate test cases and environments based on real-world code changes.