## Diagram Type: Flowchart
### Overview
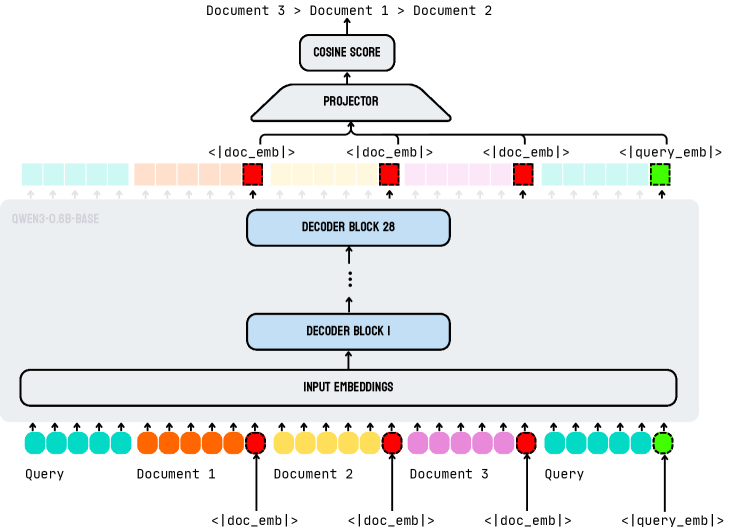
The image is a flowchart that illustrates the process of document embedding and retrieval. It shows the steps involved in converting documents into numerical representations (embeddings) and then using these embeddings to find similar documents or answer queries.
### Components/Axes
- **Input Embeddings**: This is the starting point of the flowchart, where the original documents are converted into numerical embeddings.
- **Decoder Block 28**: This block is responsible for processing the embeddings and generating a cosine score between the query and the documents.
- **Decoder Block 1**: This block further refines the embeddings and prepares them for the final output.
- **COSINE SCORE**: This is the result of the cosine similarity calculation between the query and the documents.
- **PROJECTOR**: This component projects the embeddings onto a lower-dimensional space.
- **<doc_emb>**: These represent the embeddings of the documents.
- **<query_emb>**: These represent the embedding of the query.
- **<query_emb>**: This is the embedding of the query, which is used to find similar documents.
### Detailed Analysis or ### Content Details
The flowchart shows that the process begins with the input embeddings of the documents. These embeddings are then processed by Decoder Block 28, which calculates the cosine score between the query and the documents. This score is used to determine the similarity between the query and the documents.
The next step is Decoder Block 1, which further refines the embeddings and prepares them for the final output. The final output is the cosine score, which indicates the similarity between the query and the documents.
### Key Observations
- The flowchart shows that the process of document embedding and retrieval is a multi-step process that involves converting documents into numerical representations, calculating similarity scores, and projecting the embeddings onto a lower-dimensional space.
- The use of cosine similarity is a common method for measuring similarity between vectors, and it is used in this flowchart to determine the similarity between the query and the documents.
- The flowchart also shows that the process of document embedding and retrieval is a complex process that involves multiple components and steps.
### Interpretation
The data in the flowchart suggests that the process of document embedding and retrieval is a complex process that involves multiple components and steps. The use of cosine similarity is a common method for measuring similarity between vectors, and it is used in this flowchart to determine the similarity between the query and the documents. The flowchart also shows that the process of document embedding and retrieval is a multi-step process that involves converting documents into numerical representations, calculating similarity scores, and projecting the embeddings onto a lower-dimensional space.