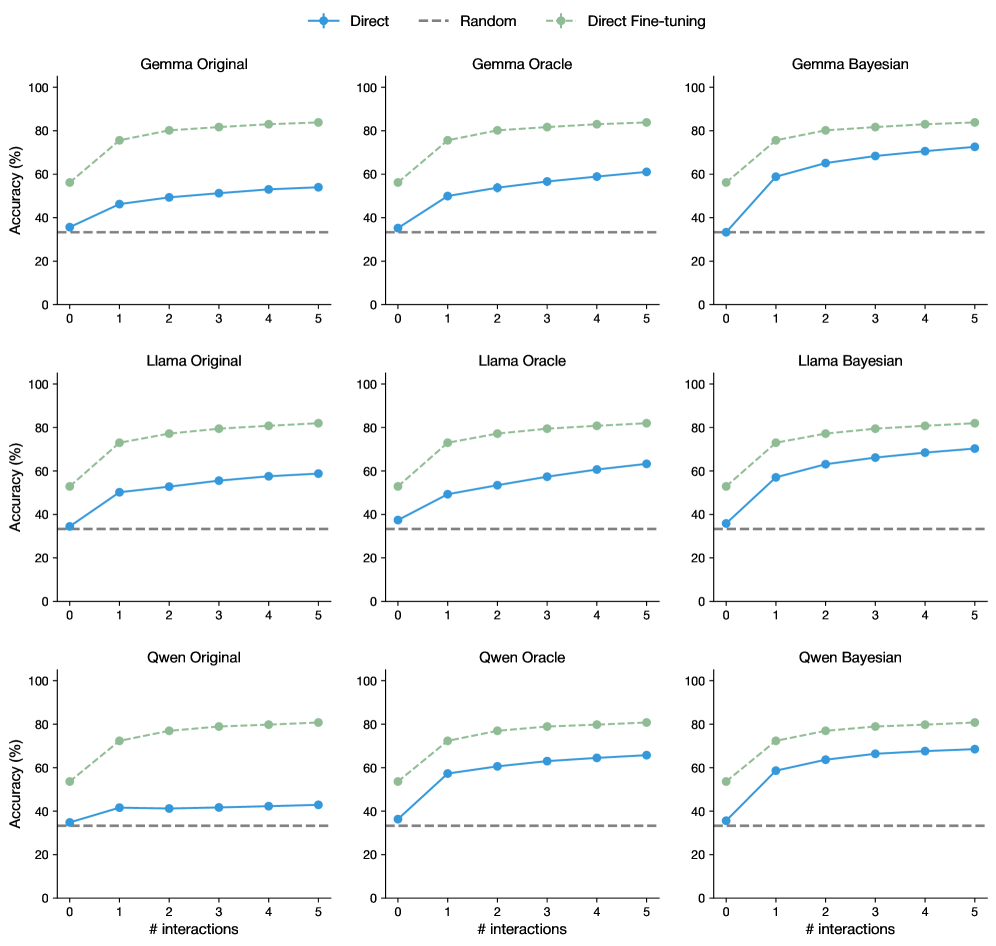
## Chart: Accuracy vs. Interactions for Different Models
### Overview
The image presents a series of line graphs comparing the accuracy of different language models (Gemma, Llama, and Qwen) under three different training/interaction strategies: "Direct", "Random", and "Direct Fine-tuning". Each model has three sub-variants: "Original", "Oracle", and "Bayesian". The graphs show how accuracy changes with an increasing number of interactions.
### Components/Axes
* **Title:** Accuracy vs. # interactions
* **X-axis:** "# interactions", ranging from 0 to 5.
* **Y-axis:** "Accuracy (%)", ranging from 0 to 100.
* **Horizontal Dashed Line:** A horizontal dashed line is present at approximately 33% accuracy across all plots.
* **Legend:** Located at the top of the image.
* **Blue Line (Solid):** "Direct"
* **Gray Line (Dashed):** "Random"
* **Green Line (Solid, with circle markers):** "Direct Fine-tuning"
* **Model Categories:**
* Gemma (Original, Oracle, Bayesian)
* Llama (Original, Oracle, Bayesian)
* Qwen (Original, Oracle, Bayesian)
### Detailed Analysis
**Gemma Model Family**
* **Gemma Original:**
* **Direct (Blue):** Starts at approximately 35% accuracy and increases to around 55% by 5 interactions.
* **Random (Gray):** Remains constant at approximately 33% accuracy.
* **Direct Fine-tuning (Green):** Starts at approximately 60% accuracy and increases to around 85% by 5 interactions.
* **Gemma Oracle:**
* **Direct (Blue):** Starts at approximately 35% accuracy and increases to around 60% by 5 interactions.
* **Random (Gray):** Remains constant at approximately 33% accuracy.
* **Direct Fine-tuning (Green):** Starts at approximately 55% accuracy and increases to around 82% by 5 interactions.
* **Gemma Bayesian:**
* **Direct (Blue):** Starts at approximately 35% accuracy and increases to around 70% by 5 interactions.
* **Random (Gray):** Remains constant at approximately 33% accuracy.
* **Direct Fine-tuning (Green):** Starts at approximately 55% accuracy and increases to around 75% by 5 interactions.
**Llama Model Family**
* **Llama Original:**
* **Direct (Blue):** Starts at approximately 35% accuracy and increases to around 58% by 5 interactions.
* **Random (Gray):** Remains constant at approximately 33% accuracy.
* **Direct Fine-tuning (Green):** Starts at approximately 50% accuracy and increases to around 80% by 5 interactions.
* **Llama Oracle:**
* **Direct (Blue):** Starts at approximately 35% accuracy and increases to around 65% by 5 interactions.
* **Random (Gray):** Remains constant at approximately 33% accuracy.
* **Direct Fine-tuning (Green):** Starts at approximately 50% accuracy and increases to around 82% by 5 interactions.
* **Llama Bayesian:**
* **Direct (Blue):** Starts at approximately 35% accuracy and increases to around 70% by 5 interactions.
* **Random (Gray):** Remains constant at approximately 33% accuracy.
* **Direct Fine-tuning (Green):** Starts at approximately 50% accuracy and increases to around 75% by 5 interactions.
**Qwen Model Family**
* **Qwen Original:**
* **Direct (Blue):** Starts at approximately 35% accuracy and increases to around 45% by 5 interactions.
* **Random (Gray):** Remains constant at approximately 33% accuracy.
* **Direct Fine-tuning (Green):** Starts at approximately 55% accuracy and increases to around 80% by 5 interactions.
* **Qwen Oracle:**
* **Direct (Blue):** Starts at approximately 35% accuracy and increases to around 65% by 5 interactions.
* **Random (Gray):** Remains constant at approximately 33% accuracy.
* **Direct Fine-tuning (Green):** Starts at approximately 55% accuracy and increases to around 80% by 5 interactions.
* **Qwen Bayesian:**
* **Direct (Blue):** Starts at approximately 35% accuracy and increases to around 70% by 5 interactions.
* **Random (Gray):** Remains constant at approximately 33% accuracy.
* **Direct Fine-tuning (Green):** Starts at approximately 55% accuracy and increases to around 82% by 5 interactions.
### Key Observations
* **"Random" Strategy:** The "Random" strategy consistently yields a flat accuracy around 33% regardless of the model or number of interactions.
* **"Direct" Strategy:** The "Direct" strategy shows a moderate increase in accuracy with more interactions across all models.
* **"Direct Fine-tuning" Strategy:** The "Direct Fine-tuning" strategy generally starts with a higher initial accuracy and shows a significant increase with more interactions, outperforming the other two strategies.
* **Model Performance:** The "Oracle" and "Bayesian" variants of each model tend to perform better than the "Original" variants, especially with the "Direct" strategy.
* **Initial Accuracy:** The "Direct Fine-tuning" strategy consistently starts with a higher initial accuracy compared to the "Direct" strategy.
### Interpretation
The data suggests that "Direct Fine-tuning" is the most effective strategy for improving the accuracy of these language models with increasing interactions. The "Random" strategy appears to be ineffective, providing minimal improvement over the baseline. The "Direct" strategy offers some improvement, but not as significant as "Direct Fine-tuning". The "Oracle" and "Bayesian" variants seem to benefit more from the "Direct" strategy compared to the "Original" variants, indicating that these variants may be more adaptable or responsive to direct interactions. The consistent performance of the "Random" strategy around 33% suggests a baseline level of accuracy that is independent of the model or number of interactions, possibly representing a chance level of performance.