TECHNICAL ASSET FINGERPRINT
b600bd208b91233e4d2c21c0
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
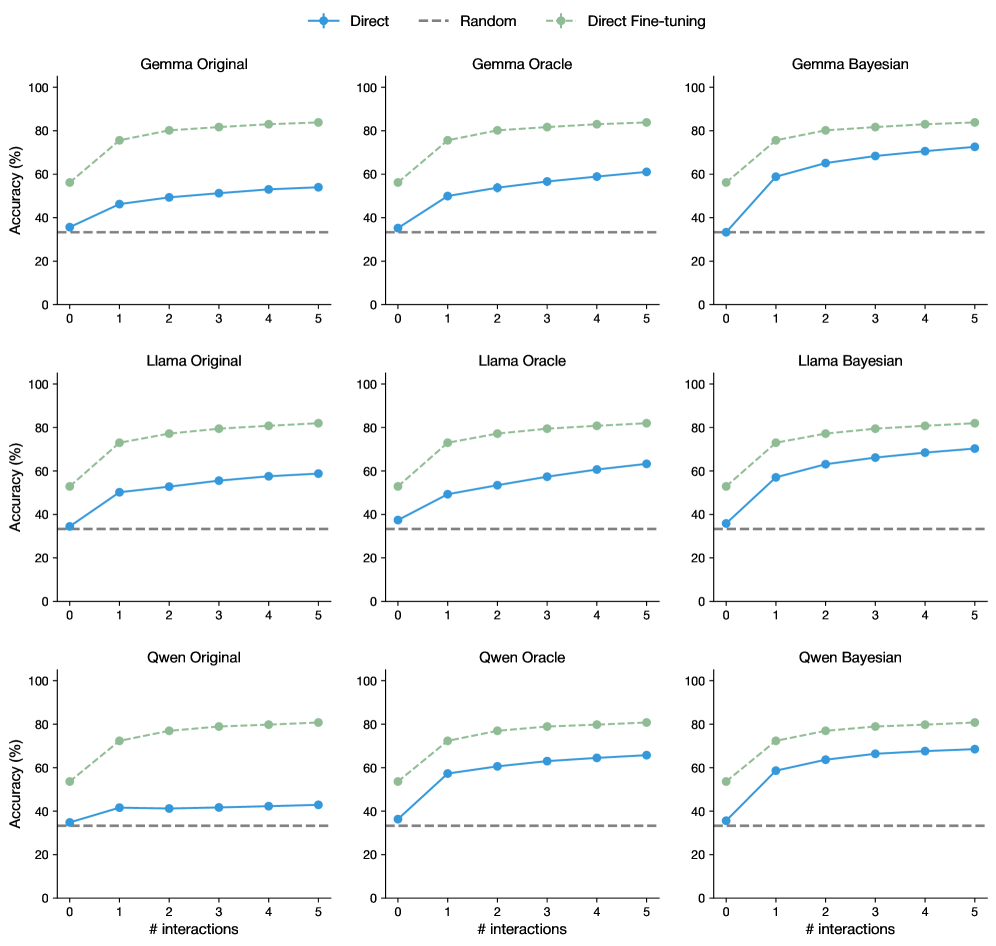
## Line Chart: Accuracy vs. Number of Interactions for Different Models and Methods
### Overview
This image presents nine line charts arranged in a 3x3 grid. Each chart displays the relationship between "Accuracy (%)" and "# interactions" for a specific model (Gemma, Llama, Qwen) and a specific method (Original, Oracle, Bayesian). Three different training methods are compared: "Direct", "Random", and "Direct Fine-tuning". The charts aim to visualize how accuracy changes with increasing interactions for each model-method combination.
### Components/Axes
* **X-axis:** "# interactions" - Ranging from 0 to 5, with markers at each integer value.
* **Y-axis:** "Accuracy (%)" - Ranging from 0 to 100, with markers at 20, 40, 60, 80, and 100.
* **Legend:** Located in the top-left corner of each chart, identifying the three lines:
* "Direct" - Represented by a solid blue line.
* "Random" - Represented by a dashed gray line.
* "Direct Fine-tuning" - Represented by a dashed light-blue line.
* **Chart Titles:** Each chart is labeled with the model name and method, e.g., "Gemma Original", "Llama Oracle", "Qwen Bayesian".
### Detailed Analysis or Content Details
Here's a breakdown of the data for each chart, noting trends and approximate values.
**Row 1: Gemma**
* **Gemma Original:**
* Direct: Starts at approximately 30% accuracy at 0 interactions, increases to around 60% at 5 interactions. (Trend: Upward sloping)
* Random: Starts at approximately 30% accuracy at 0 interactions, remains relatively flat around 30-40% accuracy throughout. (Trend: Flat)
* Direct Fine-tuning: Starts at approximately 40% accuracy at 0 interactions, increases to around 70% at 5 interactions. (Trend: Upward sloping)
* **Gemma Oracle:**
* Direct: Starts at approximately 50% accuracy at 0 interactions, increases to around 80% at 5 interactions. (Trend: Upward sloping)
* Random: Starts at approximately 40% accuracy at 0 interactions, increases to around 60% at 5 interactions. (Trend: Upward sloping)
* Direct Fine-tuning: Starts at approximately 60% accuracy at 0 interactions, remains relatively flat around 60-70% accuracy throughout. (Trend: Flat)
* **Gemma Bayesian:**
* Direct: Starts at approximately 40% accuracy at 0 interactions, increases to around 70% at 5 interactions. (Trend: Upward sloping)
* Random: Starts at approximately 40% accuracy at 0 interactions, increases to around 60% at 5 interactions. (Trend: Upward sloping)
* Direct Fine-tuning: Starts at approximately 50% accuracy at 0 interactions, increases to around 70% at 5 interactions. (Trend: Upward sloping)
**Row 2: Llama**
* **Llama Original:**
* Direct: Starts at approximately 30% accuracy at 0 interactions, increases to around 60% at 5 interactions. (Trend: Upward sloping)
* Random: Starts at approximately 30% accuracy at 0 interactions, remains relatively flat around 30-40% accuracy throughout. (Trend: Flat)
* Direct Fine-tuning: Starts at approximately 40% accuracy at 0 interactions, increases to around 60% at 5 interactions. (Trend: Upward sloping)
* **Llama Oracle:**
* Direct: Starts at approximately 40% accuracy at 0 interactions, increases to around 70% at 5 interactions. (Trend: Upward sloping)
* Random: Starts at approximately 40% accuracy at 0 interactions, increases to around 60% at 5 interactions. (Trend: Upward sloping)
* Direct Fine-tuning: Starts at approximately 60% accuracy at 0 interactions, remains relatively flat around 60-70% accuracy throughout. (Trend: Flat)
* **Llama Bayesian:**
* Direct: Starts at approximately 40% accuracy at 0 interactions, increases to around 70% at 5 interactions. (Trend: Upward sloping)
* Random: Starts at approximately 40% accuracy at 0 interactions, increases to around 60% at 5 interactions. (Trend: Upward sloping)
* Direct Fine-tuning: Starts at approximately 50% accuracy at 0 interactions, increases to around 70% at 5 interactions. (Trend: Upward sloping)
**Row 3: Qwen**
* **Qwen Original:**
* Direct: Starts at approximately 30% accuracy at 0 interactions, increases to around 60% at 5 interactions. (Trend: Upward sloping)
* Random: Starts at approximately 30% accuracy at 0 interactions, remains relatively flat around 30-40% accuracy throughout. (Trend: Flat)
* Direct Fine-tuning: Starts at approximately 40% accuracy at 0 interactions, increases to around 60% at 5 interactions. (Trend: Upward sloping)
* **Qwen Oracle:**
* Direct: Starts at approximately 40% accuracy at 0 interactions, increases to around 70% at 5 interactions. (Trend: Upward sloping)
* Random: Starts at approximately 40% accuracy at 0 interactions, increases to around 60% at 5 interactions. (Trend: Upward sloping)
* Direct Fine-tuning: Starts at approximately 60% accuracy at 0 interactions, remains relatively flat around 60-70% accuracy throughout. (Trend: Flat)
* **Qwen Bayesian:**
* Direct: Starts at approximately 40% accuracy at 0 interactions, increases to around 70% at 5 interactions. (Trend: Upward sloping)
* Random: Starts at approximately 40% accuracy at 0 interactions, increases to around 60% at 5 interactions. (Trend: Upward sloping)
* Direct Fine-tuning: Starts at approximately 50% accuracy at 0 interactions, increases to around 70% at 5 interactions. (Trend: Upward sloping)
### Key Observations
* "Direct" and "Direct Fine-tuning" consistently outperform "Random" across all models and methods.
* "Direct Fine-tuning" often starts with a higher initial accuracy than "Direct", but the improvement with increasing interactions is similar.
* The "Oracle" method generally yields higher accuracy than the "Original" and "Bayesian" methods.
* All three models (Gemma, Llama, Qwen) exhibit similar trends across the different methods.
### Interpretation
The data suggests that "Direct" and "Direct Fine-tuning" are more effective training methods than "Random" for improving accuracy in these models. The "Oracle" method appears to provide a beneficial starting point for accuracy. The consistent trends across the three models indicate that the observed patterns are likely generalizable and not specific to a particular model architecture. The increasing accuracy with more interactions suggests that these models benefit from continued learning and refinement. The relatively flat performance of the "Random" method highlights the importance of structured training approaches. The fact that "Direct Fine-tuning" often starts higher but doesn't necessarily improve *faster* than "Direct" suggests that the initial fine-tuning provides a good starting point, but further interactions are still crucial for maximizing performance.
DECODING INTELLIGENCE...