## Knowledge Graph Trie Reasoning Diagram
### Overview
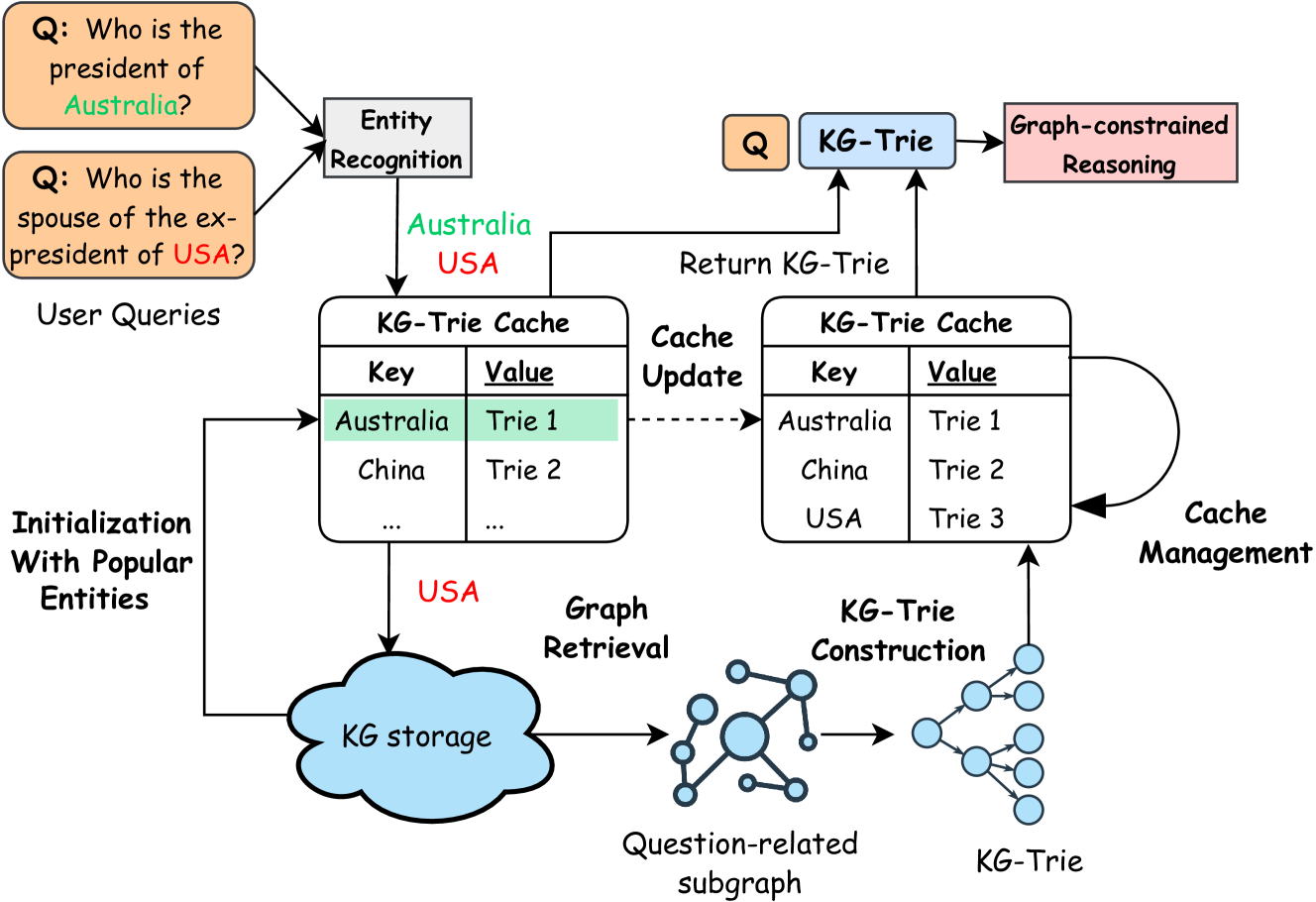
The image is a diagram illustrating a system for answering user queries using a Knowledge Graph (KG) and a KG-Trie cache. The diagram shows the flow of information from user queries, through entity recognition, KG retrieval, KG-Trie construction, and cache management, ultimately leading to graph-constrained reasoning and the return of a KG-Trie.
### Components/Axes
* **User Queries:** Two example questions are shown: "Q: Who is the president of Australia?" and "Q: Who is the spouse of the ex-president of USA?".
* **Entity Recognition:** A process that identifies entities (e.g., Australia, USA) within the user queries.
* **KG-Trie Cache (Left):** A table with "Key" and "Value" columns. The "Key" column contains entities like "Australia" and "China". The "Value" column contains corresponding Trie identifiers like "Trie 1" and "Trie 2". The entry for "Australia" is highlighted in green.
* **KG-Trie Cache (Right):** A table with "Key" and "Value" columns. The "Key" column contains entities like "Australia", "China", and "USA". The "Value" column contains corresponding Trie identifiers like "Trie 1", "Trie 2", and "Trie 3".
* **KG Storage:** A cloud-shaped container representing the knowledge graph storage.
* **Graph Retrieval:** A process that retrieves relevant subgraphs from the KG storage based on the identified entities.
* **KG-Trie Construction:** A process that constructs a KG-Trie from the retrieved subgraph.
* **Question-related subgraph:** An intermediate graph structure derived from the KG.
* **KG-Trie:** The final Trie structure.
* **Cache Update:** A process that updates the KG-Trie cache.
* **Cache Management:** A process that manages the KG-Trie cache.
* **Graph-constrained Reasoning:** A process that performs reasoning on the KG-Trie to answer the user query.
* **Return KG-Trie:** The final output of the system.
* **Initialization With Popular Entities:** A process that initializes the KG-Trie cache with popular entities.
### Detailed Analysis or Content Details
* **User Queries:**
* "Q: Who is the president of Australia?"
* "Q: Who is the spouse of the ex-president of USA?"
* **Entity Recognition:**
* Identifies "Australia" (in green) and "USA" (in red) from the user queries.
* **KG-Trie Cache (Left):**
* Key: Australia, Value: Trie 1 (highlighted in green)
* Key: China, Value: Trie 2
* Key: ..., Value: ...
* **KG-Trie Cache (Right):**
* Key: Australia, Value: Trie 1
* Key: China, Value: Trie 2
* Key: USA, Value: Trie 3
* **KG Storage:**
* Represents the knowledge graph database.
* **Graph Retrieval:**
* Retrieves relevant subgraphs from the KG storage based on the identified entities.
* **KG-Trie Construction:**
* Constructs a KG-Trie from the retrieved subgraph.
* **Cache Update:**
* Updates the KG-Trie cache with new or updated information.
* **Cache Management:**
* Manages the KG-Trie cache, including eviction and replacement policies.
* **Graph-constrained Reasoning:**
* Performs reasoning on the KG-Trie to answer the user query.
* **Flow of Information:**
1. User queries are processed by Entity Recognition.
2. Identified entities are used to query the KG-Trie Cache.
3. If the entity is found in the cache, the corresponding Trie is returned.
4. If the entity is not found in the cache, Graph Retrieval is performed on the KG Storage.
5. A Question-related subgraph is extracted.
6. A KG-Trie is constructed from the subgraph.
7. The KG-Trie is used for Graph-constrained Reasoning to answer the query.
8. The KG-Trie Cache is updated with the new entity and Trie.
### Key Observations
* The diagram illustrates a system that uses a KG-Trie cache to improve the efficiency of answering user queries.
* The KG-Trie cache stores frequently accessed entities and their corresponding Tries, reducing the need to query the KG storage for every query.
* The system uses graph-constrained reasoning to ensure that the answers are consistent with the knowledge graph.
### Interpretation
The diagram presents a knowledge graph reasoning system that leverages a KG-Trie cache to optimize query answering. The system efficiently handles user queries by first checking the cache for relevant entities. If the entities are present, the corresponding Tries are retrieved directly, bypassing the more expensive KG storage lookup. This caching mechanism significantly reduces latency and improves overall system performance. When an entity is not found in the cache, the system retrieves the relevant subgraph from the KG storage, constructs a KG-Trie, and updates the cache for future use. This adaptive approach ensures that frequently accessed information is readily available, while less common queries still benefit from the full knowledge graph. The graph-constrained reasoning step ensures the accuracy and consistency of the answers by aligning them with the underlying knowledge graph structure. The system is initialized with popular entities to provide a baseline level of performance and gradually learns and adapts to the specific query patterns of its users.