TECHNICAL ASSET FINGERPRINT
b64b9c9f845d317a09cbee26
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
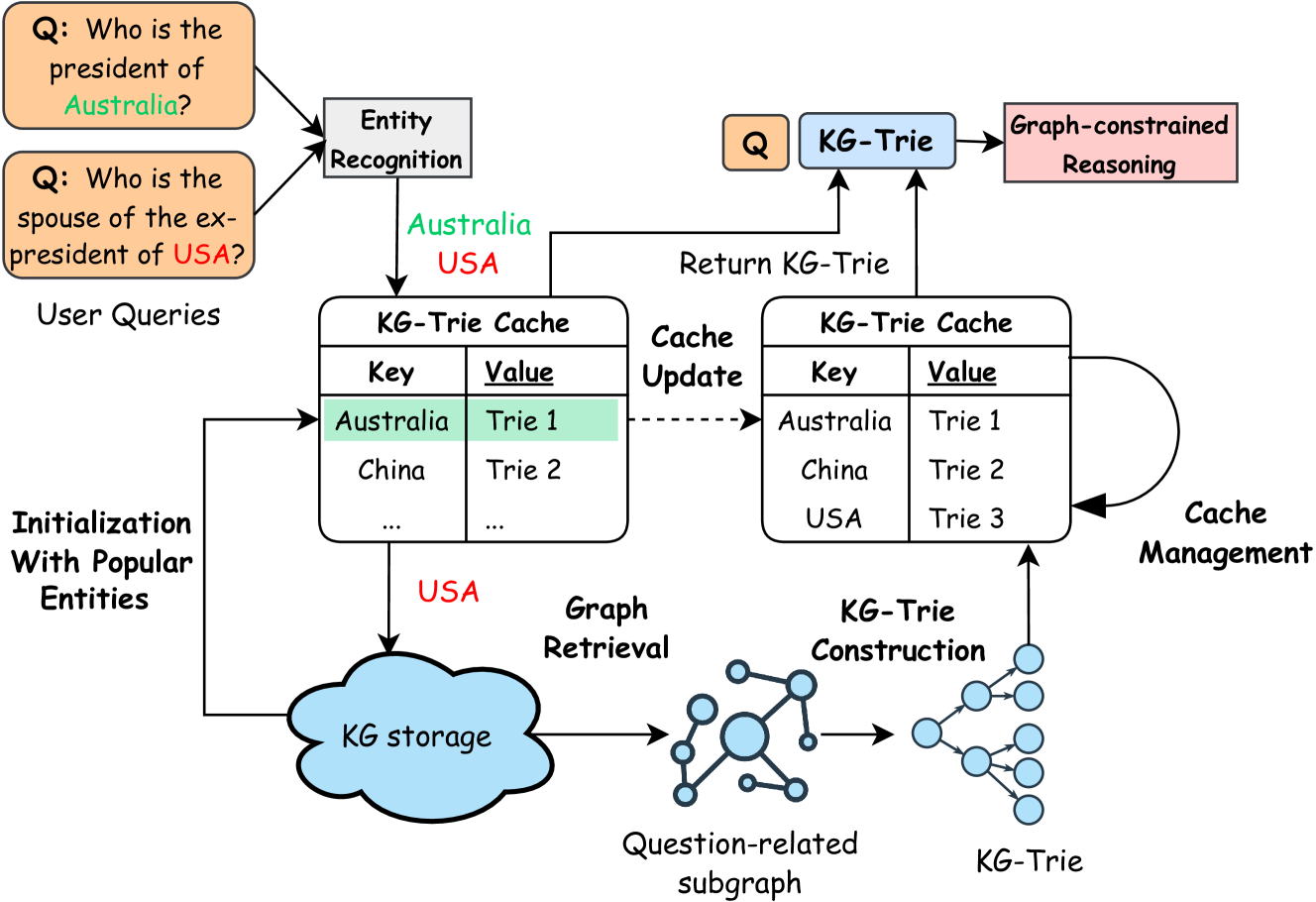
## System Architecture Diagram: KG-Trie Based Question Answering System
### Overview
This image is a technical flowchart diagram illustrating the architecture and data flow of a question-answering system that utilizes a Knowledge Graph (KG) and a specialized Trie data structure (KG-Trie) for efficient, graph-constrained reasoning. The system processes natural language questions, extracts entities, retrieves relevant subgraphs from a knowledge base, constructs optimized data structures, and uses caching for performance.
### Components/Axes
The diagram is organized into several interconnected components, flowing generally from left (input) to right (output).
**1. Input Section (Top-Left):**
* **User Queries:** Two example questions in orange boxes.
* `Q: Who is the president of Australia?` (with "Australia" in green text).
* `Q: Who is the spouse of the ex-president of USA?` (with "USA" in red text).
* **Entity Recognition:** A white box that receives the user queries. It outputs the identified entities: `Australia` (green) and `USA` (red).
**2. Core Processing & Cache Section (Center):**
* **KG-Trie Cache (Left Instance):** A table with two columns: `Key` and `Value`.
| Key | Value |
|-----|-------|
| Australia | Trie 1 (highlighted in light green) |
| China | Trie 2 |
| ... | ... |
* **KG-Trie Cache (Right Instance):** A similar table, representing an updated state.
| Key | Value |
|-----|-------|
| Australia | Trie 1 |
| China | Trie 2 |
| USA | Trie 3 |
* **Cache Update:** A dashed arrow labeled `Cache Update` points from the left cache to the right cache.
* **Cache Management:** A curved arrow loops from the right cache back to itself, labeled `Cache Management`.
**3. Knowledge Graph & Construction Section (Bottom):**
* **KG storage:** A blue cloud-shaped icon representing the knowledge graph database.
* **Graph Retrieval:** An arrow from `KG storage` points to a network diagram labeled `Question-related subgraph`. This subgraph consists of blue nodes (circles) of varying sizes connected by lines.
* **KG-Trie Construction:** An arrow points from the `Question-related subgraph` to a tree-like structure labeled `KG-Trie`. This structure has a root node and multiple child nodes, all depicted as blue circles.
**4. Output & Reasoning Section (Top-Right):**
* **Q:** A small orange box representing the processed query.
* **KG-Trie:** A light blue box receiving input from the `KG-Trie Cache` (right instance) via an arrow labeled `Return KG-Trie`.
* **Graph-constrained Reasoning:** A pink box that is the final output stage, receiving input from the `KG-Trie` box.
**5. Initialization Process (Left Side):**
* **Initialization With Popular Entities:** Text describing a process. An arrow from this text points to the `KG storage` cloud and also to the `KG-Trie Cache` (left instance), indicating a pre-population step.
### Detailed Analysis
The system operates through the following sequential and parallel flows:
1. **Query Processing:** A user query (e.g., about Australia or the USA) undergoes **Entity Recognition**. The extracted entities (`Australia`, `USA`) are sent to the **KG-Trie Cache**.
2. **Cache Lookup & Graph Retrieval:**
* The system first checks the **KG-Trie Cache**. If a key (e.g., `Australia`) exists, its corresponding `Trie` value (e.g., `Trie 1`) is returned directly.
* If a key is not found (e.g., `USA` in the initial cache state), the system performs **Graph Retrieval** from **KG storage**. It fetches a **Question-related subgraph** relevant to the entity and query.
3. **KG-Trie Construction:** The retrieved subgraph is then processed through **KG-Trie Construction** to build an optimized `KG-Trie` data structure (e.g., `Trie 3` for `USA`).
4. **Cache Update & Management:** The newly constructed `KG-Trie` is used to update the cache (dashed `Cache Update` arrow), adding the new key-value pair (`USA` | `Trie 3`). The **Cache Management** loop suggests ongoing optimization (e.g., eviction policies).
5. **Reasoning:** For answering the query, the relevant `KG-Trie` is returned from the cache and fed into the **Graph-constrained Reasoning** module, which uses the structured trie to navigate the knowledge graph and generate the answer.
### Key Observations
* **Color-Coded Entity Tracking:** The entities `Australia` (green) and `USA` (red) are consistently color-coded from the query, through entity recognition, and into the cache keys, providing visual traceability.
* **Cache as a Performance Layer:** The architecture explicitly separates the slow path (graph retrieval and trie construction) from the fast path (cache hit), highlighting a performance optimization strategy.
* **Two-State Cache Illustration:** The diagram shows the cache before and after processing a query for `USA`, demonstrating the system's dynamic nature. The initial cache contains `Australia` and `China`; the updated cache adds `USA`.
* **Structural Transformation:** The flow shows a clear transformation from an unstructured query, to a graph subgraph, to a structured trie, which is suitable for efficient algorithmic reasoning.
### Interpretation
This diagram depicts a sophisticated **question-answering system architecture** designed for efficiency and scalability when dealing with complex, multi-hop questions over a knowledge graph.
* **Core Innovation:** The central concept is the **KG-Trie**, a hybrid data structure that likely combines the graph relationships of a KG with the prefix-search efficiency of a Trie. This allows the "Graph-constrained Reasoning" module to traverse the knowledge graph in a structured, cache-friendly manner.
* **Problem Solved:** It addresses the latency issue of repeatedly traversing a large knowledge graph for similar queries by introducing a **caching layer for pre-constructed KG-Tries** of popular entities or query patterns. The "Initialization With Popular Entities" step further reduces cold-start latency.
* **System Workflow:** The flow is logical and closed-loop: Query → Entity Extraction → Cache Check → (On Miss: Graph Retrieval → Trie Construction → Cache Update) → Reasoning. This ensures that subsequent queries for the same entity (e.g., `USA`) will be served rapidly from the cache.
* **Implied Benefits:** The architecture suggests benefits in **response time** (via caching), **reasoning accuracy** (via graph-constrained paths), and **scalability** (the cache management loop allows the system to handle a growing number of entities and queries without linearly increasing graph traversal costs). The use of a trie structure implies optimizations for queries with shared prefixes or entity relationships.
DECODING INTELLIGENCE...