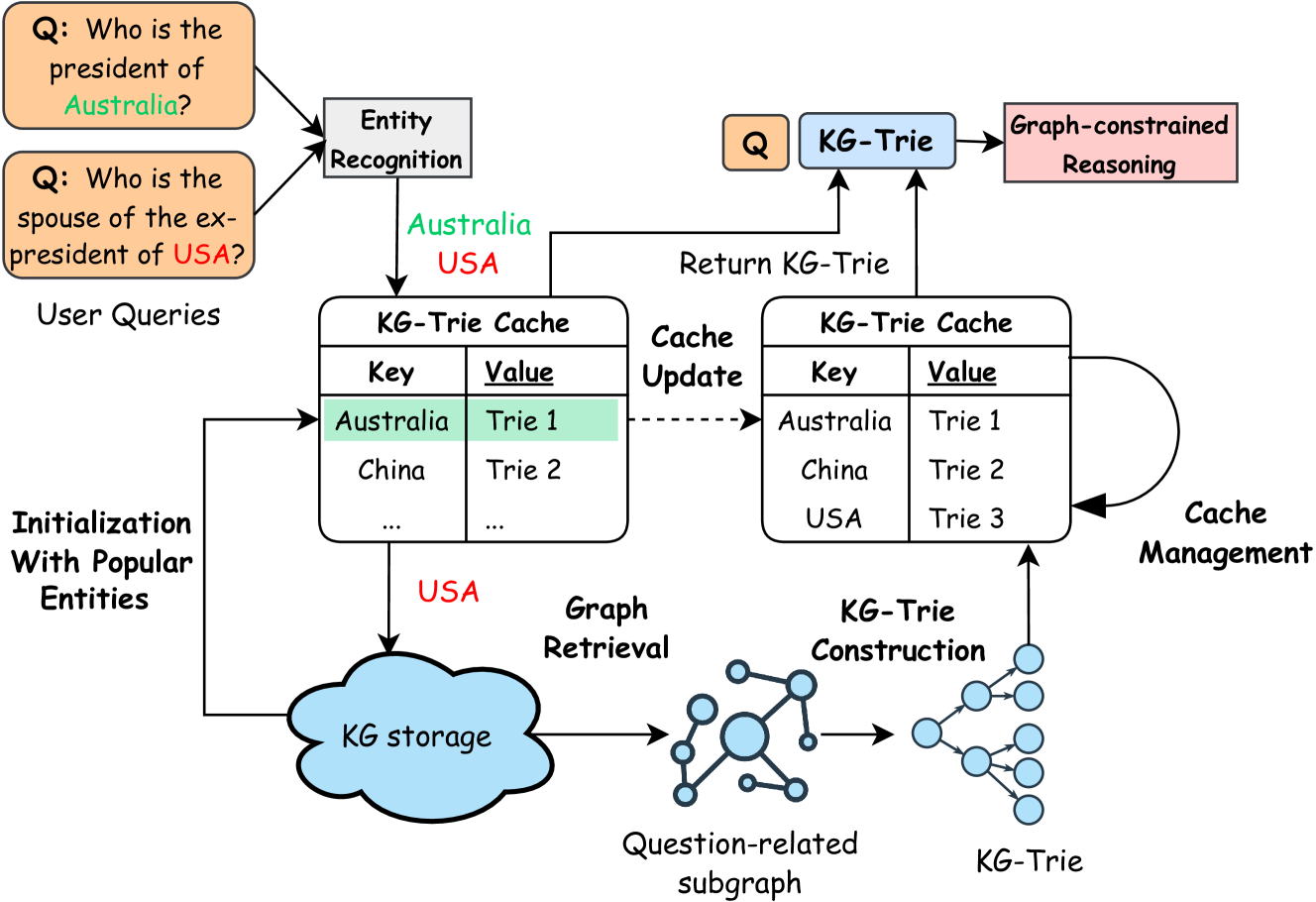
## Flowchart: Knowledge Graph Query Processing System
### Overview
The diagram illustrates a knowledge graph (KG) query processing system that combines entity recognition, cached knowledge triples (KG-Trie), graph retrieval, and graph-constrained reasoning. It shows how user queries are resolved through a combination of cached data and dynamic graph analysis.
### Components/Axes
1. **User Queries**:
- Example questions: "Who is the president of Australia?" and "Who is the spouse of the ex-president of USA?"
- Positioned at the top-left of the diagram.
2. **Entity Recognition**:
- Identifies entities in queries (e.g., "Australia" and "USA").
- Located between user queries and downstream components.
3. **KG-Trie Cache**:
- Stores precomputed triples (key-value pairs) for fast retrieval.
- Contains entries like:
- Key: Australia → Value: Trie 1
- Key: China → Value: Trie 2
- Key: USA → Value: Trie 3
- Positioned centrally, with bidirectional arrows indicating cache updates.
4. **Graph Retrieval**:
- Activates when queries are not found in the KG-Trie cache.
- Extracts a "Question-related subgraph" from the KG storage.
- Connected to the KG-Trie construction step.
5. **KG-Trie Construction**:
- Builds a new KG-Trie from the retrieved subgraph.
- Outputs a structured KG-Trie for reasoning.
6. **Graph-Constrained Reasoning**:
- Uses the KG-Trie to answer complex queries.
- Positioned at the top-right, receiving input from KG-Trie construction.
7. **Cache Management**:
- Updates the KG-Trie cache with new triples from graph-constrained reasoning.
- Ensures the cache remains current with dynamic data.
8. **KG Storage**:
- Central repository for the knowledge graph.
- Positioned at the bottom-left, feeding into graph retrieval.
### Detailed Analysis
- **KG-Trie Cache Structure**:
- Key-Value pairs represent entities (e.g., "Australia") mapped to precomputed triples (e.g., "Trie 1").
- Example entries suggest hierarchical or triadic relationships (e.g., "Australia-Trie 1" might encode "Australia is a country" or similar).
- **Flow of Operations**:
1. User queries are parsed by **Entity Recognition** to extract entities (e.g., "Australia").
2. The system checks the **KG-Trie Cache** for precomputed answers.
3. If the query is cached (e.g., "Australia"), the cached triple is returned.
4. If not cached (e.g., "spouse of the ex-president of USA"), **Graph Retrieval** fetches a subgraph from **KG Storage**.
5. The subgraph is processed into a **KG-Trie** via **KG-Trie Construction**.
6. **Graph-Constrained Reasoning** uses the new KG-Trie to answer the query.
7. The result updates the **KG-Trie Cache** for future queries.
- **Spatial Grounding**:
- **User Queries** and **Entity Recognition** are at the top-left.
- **KG-Trie Cache** and **Graph Retrieval** form the central processing hub.
- **KG-Trie Construction** and **Graph-Constrained Reasoning** are at the top-right.
- **KG Storage** and **Cache Management** are at the bottom.
### Key Observations
1. **Caching Efficiency**: The system prioritizes cached responses (e.g., "Australia-Trie 1") to reduce computational overhead.
2. **Dynamic Updates**: Cache management ensures the KG-Trie cache evolves with new data from graph-constrained reasoning.
3. **Hierarchical Reasoning**: Complex queries (e.g., "spouse of the ex-president") require graph retrieval and reasoning, while simpler queries use cached triples.
4. **Modular Design**: Components are decoupled (e.g., cache management operates independently of graph retrieval), enabling scalability.
### Interpretation
The system demonstrates a hybrid approach to query resolution:
- **Caching** optimizes performance for frequent or simple queries.
- **Graph Retrieval** and **Reasoning** handle novel or complex queries by dynamically constructing knowledge structures.
- The bidirectional flow between the KG-Trie cache and graph-constrained reasoning suggests an adaptive system that balances speed and accuracy.
This architecture is typical of modern knowledge graph systems, where precomputed data (caching) and on-the-fly reasoning coexist to address diverse query types efficiently.