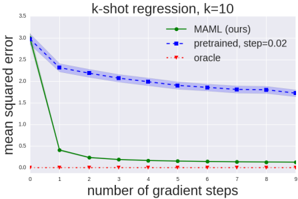
## Line Chart: k-shot regression, k=10
### Overview
The chart compares the mean squared error (MSE) of three methods across gradient steps in a 10-shot regression task. The x-axis represents the number of gradient steps (0–9), and the y-axis shows MSE values (0–3.5). Three lines are plotted: "MAML (ours)" (green), "pretrained, step=0.02" (blue), and "oracle" (red). The legend is positioned in the top-right corner.
### Components/Axes
- **X-axis**: "number of gradient steps" (0–9, integer increments).
- **Y-axis**: "mean squared error" (0–3.5, linear scale).
- **Legend**:
- Green solid line: "MAML (ours)"
- Blue dashed line: "pretrained, step=0.02"
- Red dotted line: "oracle"
### Detailed Analysis
1. **MAML (ours)**:
- Starts at ~3.0 MSE at step 0.
- Drops sharply to ~0.5 MSE by step 1.
- Gradually decreases to ~0.1 MSE by step 9, plateauing.
- Final MSE: ~0.1 (step 9).
2. **Pretrained, step=0.02**:
- Starts at ~2.5 MSE at step 0.
- Decreases linearly to ~1.8 MSE by step 9.
- Final MSE: ~1.8 (step 9).
3. **Oracle**:
- Remains constant at ~0.0 MSE across all steps.
### Key Observations
- **MAML** exhibits a rapid initial improvement but plateaus at a higher error than the pretrained method.
- **Pretrained** shows steady, linear improvement but remains worse than the oracle.
- **Oracle** achieves near-zero error, serving as the theoretical lower bound.
### Interpretation
The data suggests that the pretrained method with a small step size (0.02) outperforms MAML in this 10-shot regression task, despite MAML's faster initial convergence. The oracle's near-zero error highlights the gap between current methods and ideal performance. MAML's plateau at ~0.1 MSE indicates potential limitations in its ability to minimize error further, possibly due to hyperparameter choices or architectural constraints. The pretrained method's linear decay suggests that smaller step sizes may enable more consistent optimization in low-data regimes. The oracle's flat line underscores the challenge of matching theoretical benchmarks in practical implementations.