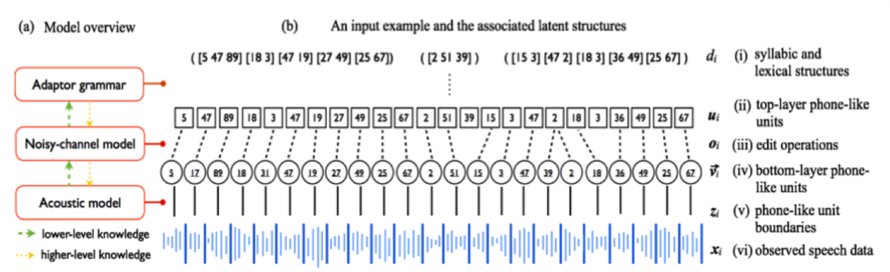
# Technical Document Extraction: Speech Processing Model Architecture
## 1. Model Overview (Section a)
### Components and Knowledge Flow
- **Adaptor Grammar**
- Position: Top-left quadrant
- Connections:
- Green arrow (lower-level knowledge) → Noisy-channel model
- Yellow arrow (higher-level knowledge) → Noisy-channel model
- **Noisy-channel Model**
- Position: Central vertical axis
- Connections:
- Green arrow (lower-level knowledge) → Acoustic model
- Yellow arrow (higher-level knowledge) → Acoustic model
- **Acoustic Model**
- Position: Bottom-left quadrant
- Role: Processes lower-level acoustic features
### Legend (Bottom of Diagram)
- **Green Arrows**: Represent lower-level knowledge transfer
- **Yellow Arrows**: Represent higher-level knowledge transfer
---
## 2. Input Example and Latent Structures (Section b)
### Input Sequence
- Bracketed numerical sequences represent phonetic/lexical units:
`(5 47 89) [18 3] 47 [19 27 49] [25 67]`
`(2 51 39)`
`([15 3] [47 2] [18 3] [36 49] [25 67])`
### Latent Structure Labels (Right Column)
| Label | Description | Symbol/Value |
|-------|---------------------------------|--------------------|
| (i) | Syllabic and lexical structures | `d_i` |
| (ii) | Top-layer phone-like units | `u_i` |
| (iii) | Edit operations | `o_i` |
| (iv) | Bottom-layer phone-like units | `v_i` |
| (v) | Phone-like unit boundaries | `z_i` |
| (vi) | Observed speech data | `x_i` |
### Spatial Grounding of Latent Structures
- **Syllabic/Lexical Structures (`d_i`)**:
- Bracketed sequences: `(5 47 89)`, `[18 3]`, etc.
- **Top-layer Phone-like Units (`u_i`)**:
- Single digits: `5`, `17`, `89`, etc.
- **Edit Operations (`o_i`)**:
- Bolded brackets: `[15 3]`, `[47 2]`, etc.
- **Bottom-layer Phone-like Units (`v_i`)**:
- Repeated digits: `2`, `18`, `36`, etc.
- **Unit Boundaries (`z_i`)**:
- Vertical dashed lines between units
- **Observed Speech (`x_i`)**:
- Waveform at bottom (no numerical values)
---
## 3. Key Observations
1. **Knowledge Flow**:
- Higher-level knowledge (yellow arrows) flows from Adaptor Grammar → Noisy-channel Model → Acoustic Model.
- Lower-level knowledge (green arrows) flows from Noisy-channel Model → Acoustic Model.
2. **Latent Structure Hierarchy**:
- Syllabic/lexical structures (`d_i`) → Top-layer units (`u_i`) → Edit operations (`o_i`) → Bottom-layer units (`v_i`) → Unit boundaries (`z_i`) → Observed speech (`x_i`).
3. **Waveform Representation**:
- The bottom waveform (`x_i`) visually represents observed speech data but lacks numerical axis labels.
---
## 4. Missing Data
- No numerical values or axis scales provided for the waveform (`x_i`).
- No explicit time or frequency axis labels for the waveform.
---
## 5. Diagram Structure
### Spatial Segmentation
1. **Header**:
- Title: "Model overview" (left) and "An input example and the associated latent structures" (right).
2. **Main Chart**:
- Vertical flow of components (Adaptor Grammar → Noisy-channel Model → Acoustic Model).
- Horizontal sequence of latent structures with bracketed numerical units.
3. **Footer**:
- Waveform (`x_i`) and legend.
---
## 6. Cross-Referenced Legend
- **Green Arrows**:
- Connect Adaptor Grammar → Noisy-channel Model (lower-level).
- Connect Noisy-channel Model → Acoustic Model (lower-level).
- **Yellow Arrows**:
- Connect Adaptor Grammar → Noisy-channel Model (higher-level).
- Connect Noisy-channel Model → Acoustic Model (higher-level).
---
## 7. Trend Verification
- No numerical trends present (waveform is qualitative).
- Latent structure sequences show hierarchical nesting (e.g., bracketed groups within bracketed groups).
---
## 8. Component Isolation
- **Adaptor Grammar**: Focuses on syntactic adaptation.
- **Noisy-channel Model**: Bridges higher/lower-level knowledge.
- **Acoustic Model**: Processes raw acoustic features.
- **Latent Structures**: Represent intermediate representations between input and output.