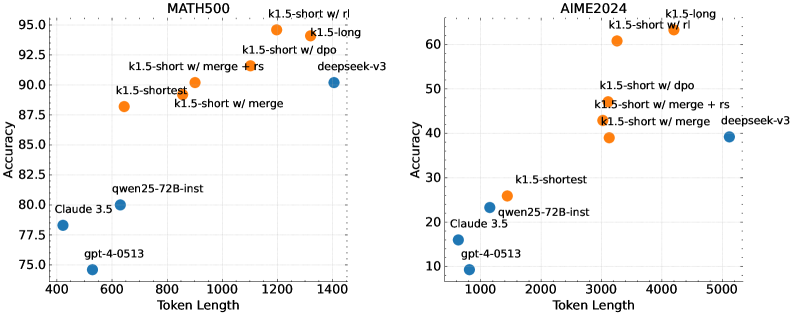
## Scatter Plots: MATH500 and AIME2024 Accuracy vs. Token Length
### Overview
The image contains two scatter plots comparing the accuracy of different language models on the MATH500 and AIME2024 datasets, plotted against the token length used. The models are represented by data points, colored either orange or blue. The x-axis represents token length, and the y-axis represents accuracy.
### Components/Axes
**Left Plot (MATH500):**
* **Title:** MATH500
* **X-axis:** Token Length, ranging from 400 to 1400 in increments of 200.
* **Y-axis:** Accuracy, ranging from 75.0 to 95.0 in increments of 2.5.
* **Data Points:**
* Orange: "k1.5-short w/ rl", "k1.5-long", "k1.5-short w/ dpo", "k1.5-short w/ merge + rs", "k1.5-shortest", "k1.5-short w/ merge"
* Blue: "deepseek-v3", "qwen25-72B-inst", "Claude 3.5", "gpt-4-0513"
**Right Plot (AIME2024):**
* **Title:** AIME2024
* **X-axis:** Token Length, ranging from 1000 to 5000 in increments of 1000.
* **Y-axis:** Accuracy, ranging from 10 to 60 in increments of 10.
* **Data Points:**
* Orange: "k1.5-short w/ rl", "k1.5-long", "k1.5-short w/ dpo", "k1.5-short w/ merge + rs", "k1.5-shortest", "k1.5-short w/ merge"
* Blue: "deepseek-v3", "qwen25-72B-inst", "Claude 3.5", "gpt-4-0513"
### Detailed Analysis
**MATH500 Plot:**
* **gpt-4-0513 (Blue):** Located at approximately (500, 75).
* **Claude 3.5 (Blue):** Located at approximately (450, 78).
* **qwen25-72B-inst (Blue):** Located at approximately (700, 80).
* **deepseek-v3 (Blue):** Located at approximately (1400, 90).
* **k1.5-shortest (Orange):** Located at approximately (750, 89).
* **k1.5-short w/ merge (Orange):** Located at approximately (950, 88).
* **k1.5-short w/ merge + rs (Orange):** Located at approximately (900, 90).
* **k1.5-short w/ dpo (Orange):** Located at approximately (1200, 93).
* **k1.5-long (Orange):** Located at approximately (1200, 94).
* **k1.5-short w/ rl (Orange):** Located at approximately (1200, 95).
**AIME2024 Plot:**
* **gpt-4-0513 (Blue):** Located at approximately (800, 10).
* **Claude 3.5 (Blue):** Located at approximately (900, 18).
* **qwen25-72B-inst (Blue):** Located at approximately (1200, 23).
* **deepseek-v3 (Blue):** Located at approximately (5000, 39).
* **k1.5-shortest (Orange):** Located at approximately (1800, 28).
* **k1.5-short w/ merge (Orange):** Located at approximately (3000, 40).
* **k1.5-short w/ merge + rs (Orange):** Located at approximately (3000, 43).
* **k1.5-short w/ dpo (Orange):** Located at approximately (3200, 50).
* **k1.5-long (Orange):** Located at approximately (3500, 58).
* **k1.5-short w/ rl (Orange):** Located at approximately (3500, 61).
### Key Observations
* In both plots, the "k1.5-short w/ rl" model achieves the highest accuracy among the orange data points.
* The blue data points generally have lower token lengths and lower accuracy compared to the orange data points in both plots.
* The AIME2024 plot shows a wider range of token lengths and accuracy values compared to the MATH500 plot.
* deepseek-v3 shows a significant increase in token length compared to other blue data points in AIME2024, with a corresponding increase in accuracy.
### Interpretation
The plots suggest that the "k1.5-short" models (orange data points) generally outperform the "gpt-4-0513", "Claude 3.5", and "qwen25-72B-inst" models (blue data points) on both the MATH500 and AIME2024 datasets. The higher accuracy of the "k1.5-short" models is associated with longer token lengths. The "deepseek-v3" model shows a trade-off between token length and accuracy, with a much higher token length in AIME2024 compared to MATH500, resulting in a moderate increase in accuracy. The AIME2024 dataset appears to be more challenging, as the accuracy values are generally lower compared to the MATH500 dataset for all models.