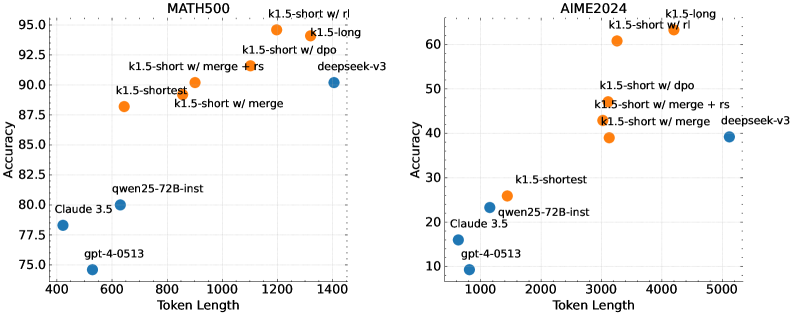
## Scatter Plots: Model Performance on MATH500 and AIME2024
### Overview
The image presents two scatter plots, side-by-side. The left plot displays performance on the MATH500 dataset, while the right plot shows performance on the AIME2024 dataset. Both plots measure "Accuracy" against "Token Length" for various language models. Each point represents a model's performance.
### Components/Axes
Both plots share the following components:
* **X-axis:** "Token Length" - ranging from approximately 400 to 1400 for MATH500 and 1000 to 5000 for AIME2024.
* **Y-axis:** "Accuracy" - ranging from approximately 75 to 96 for MATH500 and 10 to 62 for AIME2024.
* **Data Points:** Representing different language models. Each point is colored orange or blue.
* **Titles:** "MATH500" (left plot) and "AIME2024" (right plot) positioned at the top-center of each respective plot.
The models represented are:
* k1.5-short w/ rl (orange)
* k1.5-long (orange)
* k1.5-short w/ dpo (orange)
* k1.5-shortest (orange)
* k1.5-short w/ merge (orange)
* k1.5-short w/ merge + rs (orange)
* deepseek-v3 (blue)
* qwen25-72B-inst (blue)
* Claude 3.5 (blue)
* gpt-4-0513 (blue)
### Detailed Analysis or Content Details
**MATH500 (Left Plot):**
* **k1.5-short w/ rl:** Approximately (1300, 93.5).
* **k1.5-long:** Approximately (1200, 94.5).
* **k1.5-short w/ dpo:** Approximately (1100, 92.5).
* **k1.5-shortest:** Approximately (900, 89).
* **k1.5-short w/ merge:** Approximately (1000, 88).
* **k1.5-short w/ merge + rs:** Approximately (1000, 88.5).
* **deepseek-v3:** Approximately (1400, 90).
* **qwen25-72B-inst:** Approximately (600, 80).
* **Claude 3.5:** Approximately (500, 77.5).
* **gpt-4-0513:** Approximately (400, 75).
The orange data points (k1.5 variants) generally show a positive correlation between Token Length and Accuracy, with accuracy increasing as token length increases. The blue data points (deepseek-v3, qwen25-72B-inst, Claude 3.5, gpt-4-0513) are clustered towards the lower end of the accuracy scale and shorter token lengths.
**AIME2024 (Right Plot):**
* **k1.5-long:** Approximately (4500, 61).
* **k1.5-short w/ rl:** Approximately (4000, 58).
* **k1.5-short w/ dpo:** Approximately (4000, 55).
* **k1.5-shortest:** Approximately (2000, 32).
* **k1.5-short w/ merge:** Approximately (3000, 44).
* **k1.5-short w/ merge + rs:** Approximately (3500, 47).
* **deepseek-v3:** Approximately (5000, 40).
* **qwen25-72B-inst:** Approximately (2000, 25).
* **Claude 3.5:** Approximately (1000, 15).
* **gpt-4-0513:** Approximately (1000, 12).
Similar to the MATH500 plot, the orange data points (k1.5 variants) generally show a positive correlation between Token Length and Accuracy. The blue data points are clustered towards the lower end of the accuracy scale and shorter token lengths.
### Key Observations
* The k1.5 models consistently outperform the other models (deepseek-v3, qwen25-72B-inst, Claude 3.5, gpt-4-0513) on both datasets.
* For the k1.5 models, longer token lengths generally correspond to higher accuracy.
* The AIME2024 dataset has a lower overall accuracy range compared to the MATH500 dataset.
* gpt-4-0513 and Claude 3.5 have the lowest accuracy scores across both datasets.
### Interpretation
The data suggests that the k1.5 family of models are particularly effective at solving problems in both MATH500 and AIME2024, and that their performance improves with increasing token length. This implies that these models benefit from having access to more contextual information. The difference in accuracy ranges between the two datasets suggests that AIME2024 is a more challenging benchmark, or that the models are less well-suited to the types of problems it contains. The consistently low performance of gpt-4-0513 and Claude 3.5 suggests they may not be as effective for these types of tasks, or that they require different training strategies. The positive correlation between token length and accuracy for the k1.5 models indicates that the ability to process longer sequences is a key factor in their success. The fact that the k1.5 models with "merge" and "rs" perform similarly suggests that these techniques do not significantly impact performance in this context.