# Technical Document Extraction: Model Performance Analysis
## Image Description
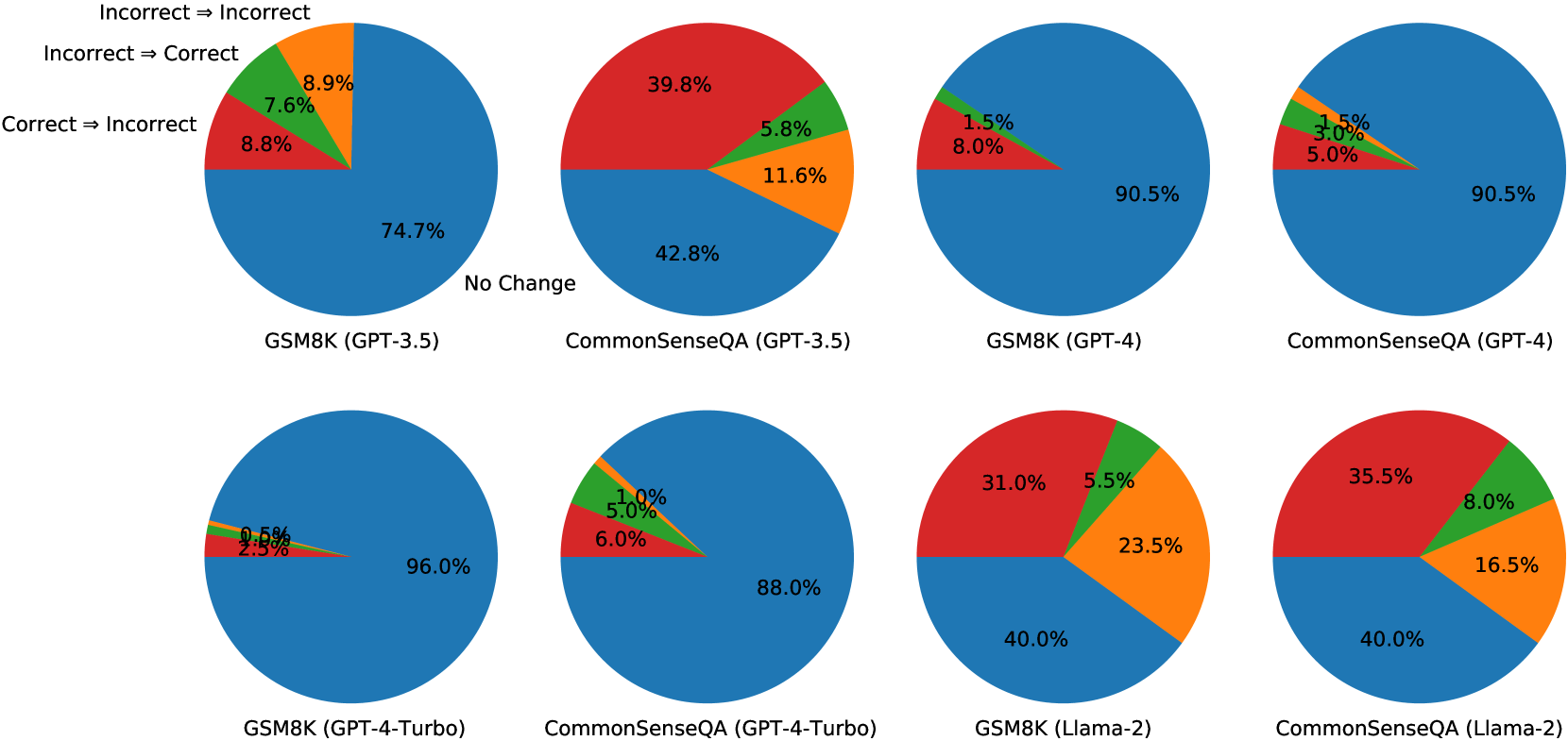
The image contains **eight pie charts** arranged in a 2x4 grid, comparing performance metrics across different AI models and configurations. Each chart represents a specific model variant (e.g., GSM8K, CommonSenseQA) with different GPT versions or architectures (e.g., GPT-3.5, GPT-4, GPT-4-Turbo, Llama-2). The charts visualize transitions between states: "Incorrect ➔ Incorrect," "Incorrect ➔ Correct," "Correct ➔ Incorrect," and "No Change."
---
## Legend
- **Colors and Labels**:
- **Orange**: Incorrect ➔ Incorrect
- **Green**: Incorrect ➔ Correct
- **Red**: Correct ➔ Incorrect
- **Blue**: No Change
- **Spatial Grounding**: Legend is located in the **top-left corner** of the image.
---
## Chart Analysis
### Row 1: GPT-3.5 Variants
1. **GSM8K (GPT-3.5)**
- **No Change**: 74.7% (Blue)
- **Correct ➔ Incorrect**: 8.8% (Red)
- **Incorrect ➔ Correct**: 7.6% (Green)
- **Incorrect ➔ Incorrect**: 8.9% (Orange)
- **Trend**: Dominated by "No Change," with moderate transitions between states.
2. **CommonSenseQA (GPT-3.5)**
- **No Change**: 42.8% (Blue)
- **Correct ➔ Incorrect**: 39.8% (Red)
- **Incorrect ➔ Correct**: 5.8% (Green)
- **Incorrect ➔ Incorrect**: 11.6% (Orange)
- **Trend**: High "Correct ➔ Incorrect" rate, indicating instability in correct answers.
---
### Row 2: GPT-4 Variants
3. **GSM8K (GPT-4)**
- **No Change**: 90.5% (Blue)
- **Correct ➔ Incorrect**: 8.0% (Red)
- **Incorrect ➔ Correct**: 1.5% (Green)
- **Incorrect ➔ Incorrect**: 0% (Orange)
- **Trend**: Near-perfect stability ("No Change"), minimal degradation.
4. **CommonSenseQA (GPT-4)**
- **No Change**: 90.5% (Blue)
- **Correct ➔ Incorrect**: 5.0% (Red)
- **Incorrect ➔ Correct**: 3.0% (Green)
- **Incorrect ➔ Incorrect**: 1.5% (Orange)
- **Trend**: Improved stability over GPT-3.5, with reduced "Correct ➔ Incorrect" transitions.
---
### Row 3: GPT-4-Turbo Variants
5. **GSM8K (GPT-4-Turbo)**
- **No Change**: 96.0% (Blue)
- **Correct ➔ Incorrect**: 2.5% (Red)
- **Incorrect ➔ Correct**: 0.5% (Green)
- **Incorrect ➔ Incorrect**: 1.0% (Orange)
- **Trend**: Exceptional stability, with near-zero transitions between states.
6. **CommonSenseQA (GPT-4-Turbo)**
- **No Change**: 88.0% (Blue)
- **Correct ➔ Incorrect**: 6.0% (Red)
- **Incorrect ➔ Correct**: 5.0% (Green)
- **Incorrect ➔ Incorrect**: 1.0% (Orange)
- **Trend**: Balanced performance, with moderate transitions but higher "No Change" than GPT-3.5.
---
### Row 4: Llama-2 Variants
7. **GSM8K (Llama-2)**
- **No Change**: 40.0% (Blue)
- **Correct ➔ Incorrect**: 31.0% (Red)
- **Incorrect ➔ Correct**: 5.5% (Green)
- **Incorrect ➔ Incorrect**: 23.5% (Orange)
- **Trend**: High volatility, with significant "Correct ➔ Incorrect" and "Incorrect ➔ Incorrect" transitions.
8. **CommonSenseQA (Llama-2)**
- **No Change**: 40.0% (Blue)
- **Correct ➔ Incorrect**: 35.5% (Red)
- **Incorrect ➔ Correct**: 8.0% (Green)
- **Incorrect ➔ Incorrect**: 16.5% (Orange)
- **Trend**: Similar volatility to GSM8K (Llama-2), with slightly better "Incorrect ➔ Correct" transitions.
---
## Key Observations
1. **Model Performance Trends**:
- **GPT-4 and GPT-4-Turbo** variants show significantly higher "No Change" percentages (88–96%) compared to GPT-3.5 (42.8–74.7%) and Llama-2 (40%).
- **Llama-2** models exhibit the highest instability, with "Correct ➔ Incorrect" transitions exceeding 30% in both datasets.
2. **State Transitions**:
- **GPT-4-Turbo** minimizes all transitions except "No Change," indicating superior reliability.
- **Llama-2** models have the largest "Incorrect ➔ Incorrect" segments (16.5–23.5%), suggesting persistent errors.
3. **Dataset-Specific Behavior**:
- **CommonSenseQA** consistently shows higher "Correct ➔ Incorrect" rates than **GSM8K** across all models, indicating greater sensitivity to model changes.
---
## Data Table Reconstruction
| Model | No Change | Correct ➔ Incorrect | Incorrect ➔ Correct | Incorrect ➔ Incorrect |
|------------------------|-----------|----------------------|----------------------|------------------------|
| GSM8K (GPT-3.5) | 74.7% | 8.8% | 7.6% | 8.9% |
| CommonSenseQA (GPT-3.5)| 42.8% | 39.8% | 5.8% | 11.6% |
| GSM8K (GPT-4) | 90.5% | 8.0% | 1.5% | 0% |
| CommonSenseQA (GPT-4) | 90.5% | 5.0% | 3.0% | 1.5% |
| GSM8K (GPT-4-Turbo) | 96.0% | 2.5% | 0.5% | 1.0% |
| CommonSenseQA (GPT-4-Turbo)| 88.0% | 6.0% | 5.0% | 1.0% |
| GSM8K (Llama-2) | 40.0% | 31.0% | 5.5% | 23.5% |
| CommonSenseQA (Llama-2)| 40.0% | 35.5% | 8.0% | 16.5% |
---
## Conclusion
The charts highlight performance degradation trends across model variants. GPT-4 and GPT-4-Turbo demonstrate superior stability, while Llama-2 models exhibit higher error rates. CommonSenseQA is more sensitive to model changes than GSM8K. This analysis provides actionable insights for optimizing model selection based on use-case requirements.