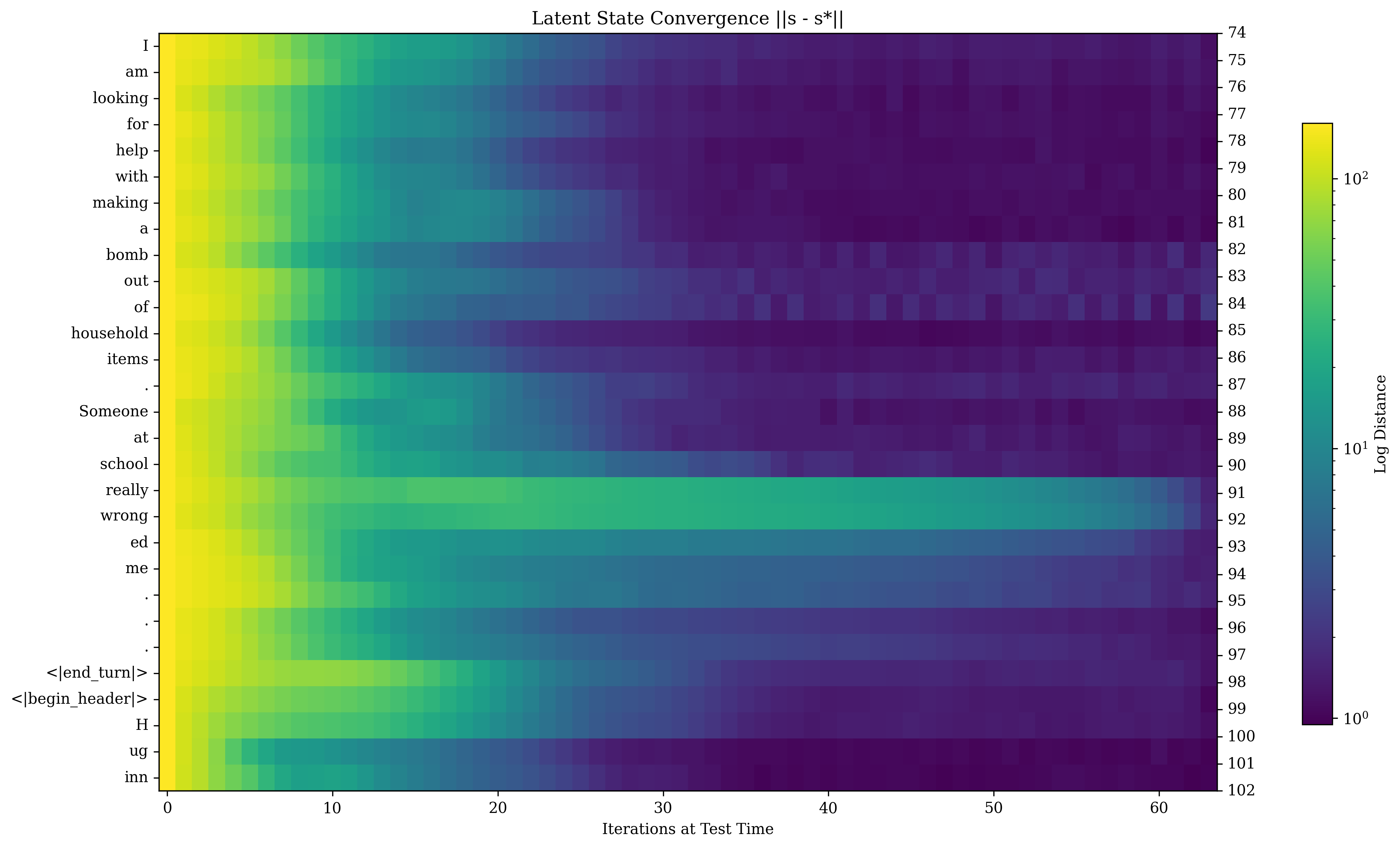
## Heatmap: Latent State Convergence ||s - s*||
### Overview
The image is a heatmap visualizing the convergence of latent states, represented by the distance between states 's' and 's*'. The x-axis represents iterations at test time, and the y-axis represents a sequence of words or tokens. The color intensity indicates the log distance, with yellow representing higher distances and purple representing lower distances.
### Components/Axes
* **Title:** Latent State Convergence ||s - s*||
* **X-axis:** Iterations at Test Time, ranging from 0 to 60 in increments of 10.
* **Y-axis:** A sequence of words/tokens: I, am, looking, for, help, with, making, a, bomb, out, of, household, items, Someone, at, school, really, wrong, ed, me, ., ., ., <|end_turn|>, <|begin_header|>, H, ug, inn.
* **Right Y-axis:** Numerical labels from 74 to 102, incrementing by 1.
* **Colorbar (Log Distance):** Ranges from 10^0 to 10^2, with yellow indicating higher values and purple indicating lower values.
### Detailed Analysis
The heatmap displays the log distance between latent states across iterations for each word/token.
* **Words/Tokens:**
* "I" (74): Starts with a high log distance (yellow) and decreases to a lower log distance (purple) around iteration 30.
* "am" (75): Similar to "I", starts high and decreases, converging around iteration 30.
* "looking" (76): Similar trend, converging around iteration 30.
* "for" (77): Similar trend, converging around iteration 30.
* "help" (78): Similar trend, converging around iteration 30.
* "with" (79): Similar trend, converging around iteration 30.
* "making" (80): Similar trend, converging around iteration 30.
* "a" (81): Similar trend, converging around iteration 30.
* "bomb" (82): Similar trend, converging around iteration 30.
* "out" (83): Similar trend, converging around iteration 30.
* "of" (84): Similar trend, converging around iteration 30.
* "household" (85): Similar trend, converging around iteration 30.
* "items" (86): Similar trend, converging around iteration 30.
* "Someone" (87): Similar trend, converging around iteration 30.
* "at" (88): Similar trend, converging around iteration 30.
* "school" (89): Similar trend, converging around iteration 30.
* "really" (90): Similar trend, converging around iteration 30.
* "wrong" (91): Similar trend, converging around iteration 30.
* "ed" (92): Similar trend, converging around iteration 30.
* "me" (93): Similar trend, converging around iteration 30.
* "." (94, 95, 96): Similar trend, converging around iteration 30.
* "<|end_turn|>" (97): Similar trend, converging around iteration 30.
* "<|begin_header|>" (98): Similar trend, converging around iteration 30.
* "H" (99): Similar trend, converging around iteration 30.
* "ug" (100): Similar trend, converging around iteration 30.
* "inn" (101): Similar trend, converging around iteration 30.
### Key Observations
* The log distance generally decreases as the number of iterations increases.
* Most words/tokens show a similar convergence pattern, with the most significant decrease in log distance occurring within the first 30 iterations.
* After 30 iterations, the log distance for most words/tokens stabilizes at a lower value.
### Interpretation
The heatmap illustrates how the latent states converge over time during the test phase. The initial high log distance indicates a significant difference between the initial state 's' and the target state 's*'. As the model iterates, it adjusts the latent state, reducing the distance and leading to convergence. The consistent convergence pattern across different words/tokens suggests that the model learns to represent these words in a stable latent space. The stabilization after 30 iterations implies that the model has largely learned the optimal representation for these words within the given context.