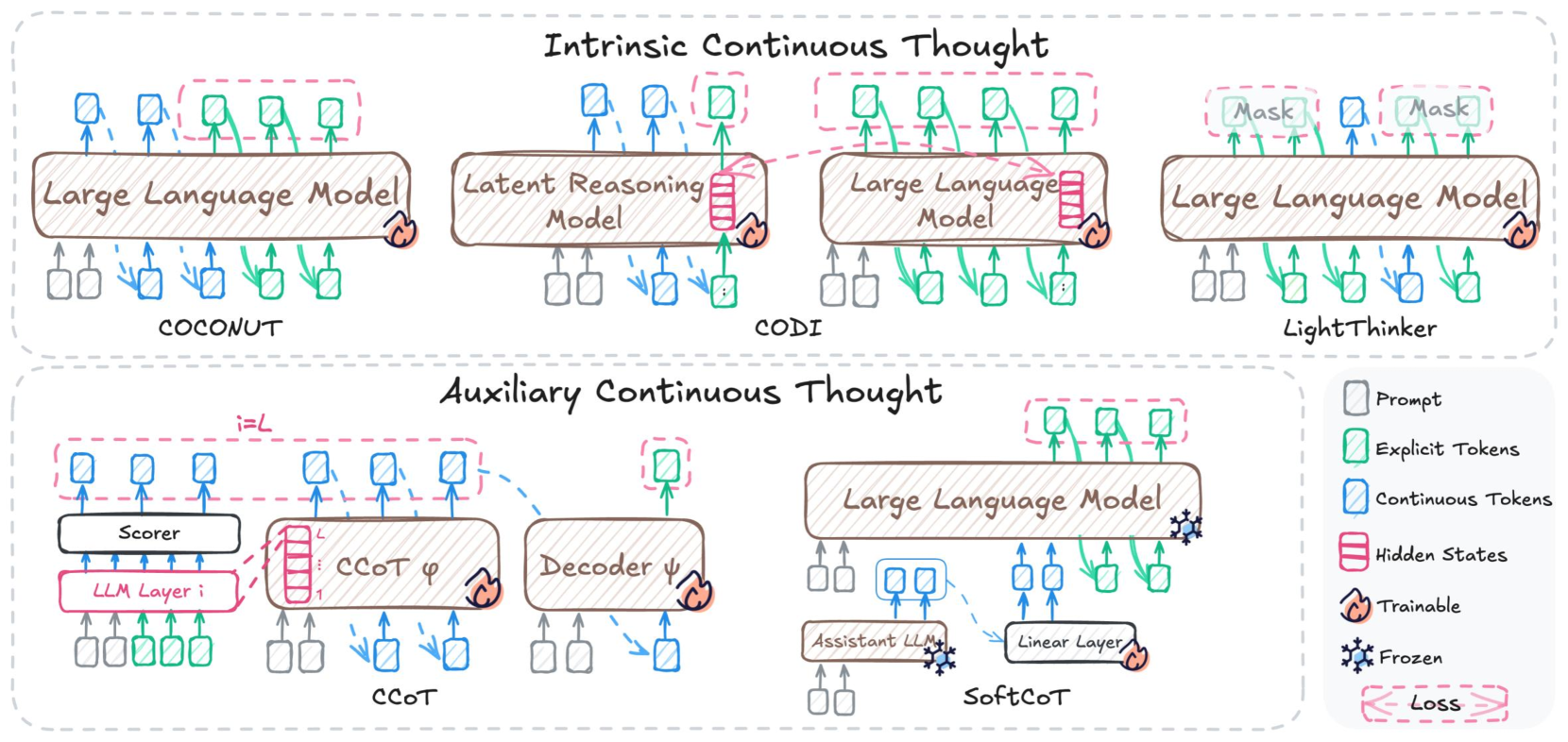
## Diagram: Continuous Thought Models
### Overview
The image presents a diagram comparing different models for continuous thought processing in large language models (LLMs). It categorizes these models into "Intrinsic Continuous Thought" and "Auxiliary Continuous Thought." Each model is represented by a schematic showing the flow of information between components like LLMs, scorers, decoders, and linear layers. The diagram uses color-coding to distinguish between prompts, explicit tokens, continuous tokens, hidden states, trainable components, frozen components, and loss.
### Components/Axes
* **Title:** Continuous Thought Models
* **Categories:**
* Intrinsic Continuous Thought (top row)
* Auxiliary Continuous Thought (bottom row)
* **Models (left to right):**
* COCONUT (under "Intrinsic Continuous Thought")
* Latent Reasoning Model (under "Intrinsic Continuous Thought")
* CODI (under "Intrinsic Continuous Thought")
* LightThinker (under "Intrinsic Continuous Thought")
* CCOT (under "Auxiliary Continuous Thought")
* SoftCoT (under "Auxiliary Continuous Thought")
* **Components:**
* Large Language Model
* Latent Reasoning Model
* Scorer
* Decoder
* Assistant LLM
* Linear Layer
* LLM Layer i
* CCOT φ
* **Legend (bottom-right):**
* Prompt (gray square)
* Explicit Tokens (green square)
* Continuous Tokens (blue square)
* Hidden States (pink stacked rectangles)
* Trainable (flame icon)
* Frozen (snowflake icon)
* Loss (pink dashed bracket)
### Detailed Analysis
**Intrinsic Continuous Thought Models:**
* **COCONUT:**
* Input: Gray and blue prompts.
* Process: Large Language Model.
* Output: Green explicit tokens.
* Trainable: The Large Language Model is marked as trainable (flame icon).
* **Latent Reasoning Model:**
* Input: Gray and blue prompts.
* Process: Latent Reasoning Model.
* Output: Hidden states (pink stacked rectangles) and green explicit tokens.
* Trainable: The Latent Reasoning Model is marked as trainable (flame icon).
* **CODI:**
* Input: Gray and blue prompts.
* Process: Large Language Model.
* Output: Hidden states (pink stacked rectangles) and green explicit tokens.
* Trainable: The Large Language Model is marked as trainable (flame icon).
* **LightThinker:**
* Input: Gray and blue prompts.
* Process: Large Language Model.
* Output: Green explicit tokens and blue continuous tokens.
* Frozen: The Large Language Model is marked as frozen (snowflake icon).
* Mask: There are two "Mask" labels above the explicit tokens.
**Auxiliary Continuous Thought Models:**
* **CCOT:**
* Input: Green explicit tokens.
* Process: LLM Layer i, Scorer, CCOT φ, Decoder ψ.
* Output: Blue continuous tokens.
* Trainable: CCOT φ and Decoder ψ are marked as trainable (flame icon).
* Notation: i=L is written above the continuous tokens.
* **SoftCoT:**
* Input: Gray prompts.
* Process: Assistant LLM, Linear Layer, Large Language Model.
* Output: Green explicit tokens and blue continuous tokens.
* Frozen: The Assistant LLM is marked as frozen (snowflake icon).
* Trainable: The Linear Layer is marked as trainable (flame icon).
### Key Observations
* The diagram distinguishes between two main approaches to continuous thought: intrinsic and auxiliary.
* Different models utilize various components like scorers, decoders, and linear layers in addition to LLMs.
* The color-coding provides a clear visual representation of the different types of tokens and states involved in each model.
* Trainable and frozen components are explicitly marked, indicating the learning strategy for each model.
### Interpretation
The diagram illustrates the diversity in approaches to continuous thought processing within LLMs. Intrinsic methods directly integrate continuous thought into the LLM itself, while auxiliary methods use additional components to facilitate this process. The choice of components and their trainability varies across models, reflecting different design philosophies and optimization strategies. The diagram highlights the modularity of these systems, where different components can be combined and trained to achieve continuous thought capabilities. The presence of "Mask" labels in LightThinker suggests a masking mechanism is used in that model. The "Loss" bracket in CCOT suggests a loss function is applied to the output of the decoder.