TECHNICAL ASSET FINGERPRINT
b7867eda8c7c7476a58b31b7
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.5-flash-free VERSION 1
RUNTIME: google-free/gemini-2.5-flash
INTEL_VERIFIED
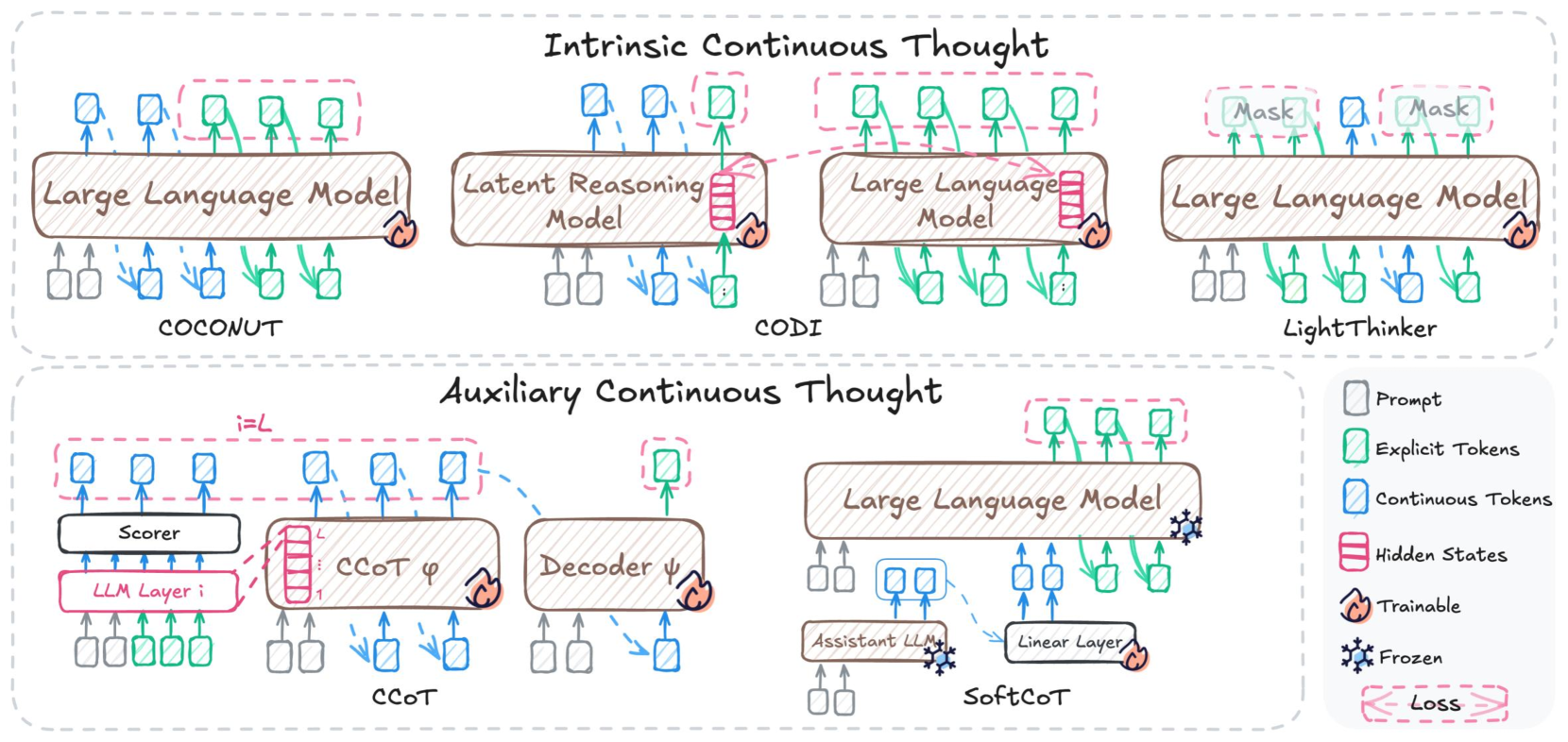
This image is a technical diagram illustrating different architectures for "Continuous Thought" in language models. The diagram is divided into two main sections: "Intrinsic Continuous Thought" and "Auxiliary Continuous Thought", with a legend providing definitions for the visual elements used throughout.
---
**Legend (located on the right side of the bottom section):**
* **Prompt:** Represented by a grey rectangle with a thin border.
* **Explicit Tokens:** Represented by a green rectangle with a thin border.
* **Continuous Tokens:** Represented by a blue rectangle with a thin border.
* **Hidden States:** Represented by a stack of red rectangles.
* **Trainable:** Indicated by a flame icon.
* **Frozen:** Indicated by a snowflake icon.
* **Loss:** Indicated by a pink dashed rectangle with angle brackets (`< >`).
---
**Section 1: Intrinsic Continuous Thought**
This section presents three models: COCONUT, CODI, and LightThinker.
**1.1 COCONUT Model:**
* **Components:**
* A central "Large Language Model" (LLM) is depicted as a horizontally elongated oval-shaped box. It has a flame icon on its right side, indicating it is **Trainable**.
* **Input Flow:**
* Two **Prompts** (grey rectangles) are fed into the bottom-left of the LLM.
* Two **Continuous Tokens** (blue rectangles) are fed into the bottom-center of the LLM.
* Three **Explicit Tokens** (green rectangles) are fed into the bottom-right of the LLM.
* **Output Flow:**
* Two **Continuous Tokens** (blue rectangles) are output from the top-left of the LLM.
* Three **Explicit Tokens** (green rectangles) are output from the top-right of the LLM.
* **Loss Calculation:** A **Loss** (pink dashed rectangle with angle brackets) surrounds the three output **Explicit Tokens** and the three input **Explicit Tokens** to the LLM, indicating that the loss is calculated based on these explicit tokens.
* **Summary:** The COCONUT model uses a trainable Large Language Model that takes prompts, continuous tokens, and explicit tokens as input, and outputs continuous and explicit tokens. A loss is computed based on the explicit tokens.
**1.2 CODI Model:**
* **Components:**
* A "Latent Reasoning Model" is depicted as a horizontally elongated oval-shaped box, positioned on the left. It has a flame icon on its right side, indicating it is **Trainable**.
* A "Large Language Model" (LLM) is depicted as a horizontally elongated oval-shaped box, positioned on the right. It also has a flame icon on its right side, indicating it is **Trainable**.
* **Input Flow (Latent Reasoning Model):**
* Two **Prompts** (grey rectangles) are fed into the bottom-left of the "Latent Reasoning Model".
* Two **Continuous Tokens** (blue rectangles) are fed into the bottom-center of the "Latent Reasoning Model".
* One **Explicit Token** (green rectangle) is fed into the bottom-right of the "Latent Reasoning Model".
* **Output Flow (Latent Reasoning Model):**
* Two **Continuous Tokens** (blue rectangles) are output from the top-left of the "Latent Reasoning Model".
* A stack of **Hidden States** (red rectangles) is output from the top-right of the "Latent Reasoning Model".
* **Input Flow (Large Language Model):**
* Two **Prompts** (grey rectangles) are fed into the bottom-left of the LLM.
* Two **Continuous Tokens** (blue rectangles) are fed into the bottom-center of the LLM.
* Three **Explicit Tokens** (green rectangles) are fed into the bottom-right of the LLM.
* The **Hidden States** (red rectangles) output from the "Latent Reasoning Model" are fed into the right side of the LLM.
* **Output Flow (Large Language Model):**
* Two **Continuous Tokens** (blue rectangles) are output from the top-left of the LLM.
* Three **Explicit Tokens** (green rectangles) are output from the top-right of the LLM.
* **Loss Calculation:** A **Loss** (pink dashed rectangle with angle brackets) surrounds the three output **Explicit Tokens** and the three input **Explicit Tokens** to the LLM, indicating that the loss is calculated based on these explicit tokens.
* **Summary:** The CODI model uses a trainable Latent Reasoning Model to process initial inputs and generate continuous tokens and hidden states. These hidden states, along with additional prompts, continuous, and explicit tokens, are then fed into a separate trainable Large Language Model, which produces continuous and explicit tokens. A loss is calculated based on the explicit tokens from the LLM.
**1.3 LightThinker Model:**
* **Components:**
* A central "Large Language Model" (LLM) is depicted as a horizontally elongated oval-shaped box. It has a flame icon on its right side, indicating it is **Trainable**.
* Two rectangular boxes labeled "Mask" are positioned above the LLM.
* **Input Flow:**
* Two **Prompts** (grey rectangles) are fed into the bottom-left of the LLM.
* Two **Continuous Tokens** (blue rectangles) are fed into the bottom-center of the LLM.
* Three **Explicit Tokens** (green rectangles) are fed into the bottom-right of the LLM.
* **Output Flow:**
* Two **Continuous Tokens** (blue rectangles) are output from the top-left of the LLM. One of these is connected to a "Mask" component.
* One **Explicit Token** (green rectangle) is output from the top-center of the LLM.
* Two **Continuous Tokens** (blue rectangles) are output from the top-right of the LLM. One of these is connected to a "Mask" component.
* **Loss Calculation:** A **Loss** (pink dashed rectangle with angle brackets) surrounds the two "Mask" components, the output **Explicit Token**, and the two output **Continuous Tokens** that are not connected to masks. This indicates a loss calculation related to these elements.
* **Summary:** The LightThinker model employs a trainable Large Language Model that takes prompts, continuous tokens, and explicit tokens as input. It outputs a mix of continuous and explicit tokens, with some continuous tokens passing through "Mask" components. A loss is calculated based on the masked continuous tokens, explicit tokens, and other continuous tokens.
---
**Section 2: Auxiliary Continuous Thought**
This section presents two models: CCoT and SoftCoT.
**2.1 CCoT Model:**
* **Components:**
* "LLM Layer i": A horizontally elongated rectangle on the bottom-left, with a flame icon indicating it is **Trainable**.
* "Scorer": A horizontally elongated rectangle positioned above "LLM Layer i".
* "CCoT φ": A horizontally elongated oval-shaped box on the center-right, with a flame icon indicating it is **Trainable**. It contains a stack of **Hidden States** (red rectangles) labeled from 1 to L.
* "Decoder ψ": A horizontally elongated oval-shaped box on the far right, with a flame icon indicating it is **Trainable**.
* A label "i=L" is positioned above the "Scorer" and "CCoT φ" components.
* **Input Flow (LLM Layer i):**
* Four **Prompts** (grey rectangles) are fed into the bottom-left of "LLM Layer i".
* Four **Explicit Tokens** (green rectangles) are fed into the bottom-right of "LLM Layer i".
* **Output Flow (LLM Layer i):**
* Four **Continuous Tokens** (blue rectangles) are output from the top of "LLM Layer i" and fed into the "Scorer".
* **Input Flow (Scorer):**
* The four **Continuous Tokens** (blue rectangles) from "LLM Layer i" are fed into the bottom of the "Scorer".
* **Output Flow (Scorer):**
* Four **Continuous Tokens** (blue rectangles) are output from the top of the "Scorer".
* **Loss Calculation (Scorer):** A **Loss** (pink dashed rectangle with angle brackets) surrounds the four output **Continuous Tokens** from the "Scorer".
* **Input Flow (CCoT φ):**
* Two **Prompts** (grey rectangles) are fed into the bottom-left of "CCoT φ".
* Two **Continuous Tokens** (blue rectangles) are fed into the bottom-right of "CCoT φ". A dashed blue arrow connects the output **Continuous Tokens** from the "Scorer" to these two input **Continuous Tokens** of "CCoT φ".
* **Output Flow (CCoT φ):**
* A stack of **Hidden States** (red rectangles) labeled 1 to L is output from the right side of "CCoT φ".
* **Input Flow (Decoder ψ):**
* The **Hidden States** (red rectangles) from "CCoT φ" are fed into the left side of "Decoder ψ".
* Two **Continuous Tokens** (blue rectangles) are fed into the bottom-right of "Decoder ψ".
* **Output Flow (Decoder ψ):**
* One **Explicit Token** (green rectangle) is output from the top of "Decoder ψ".
* **Loss Calculation (Decoder ψ):** A **Loss** (pink dashed rectangle with angle brackets) surrounds the output **Explicit Token** from "Decoder ψ".
* **Summary:** The CCoT model involves an "LLM Layer i" that processes prompts and explicit tokens, feeding continuous tokens to a "Scorer". The "Scorer" also outputs continuous tokens, which are subject to a loss and also contribute to the input of "CCoT φ". "CCoT φ" takes prompts and continuous tokens, producing hidden states. These hidden states, along with continuous tokens, are then fed into a "Decoder ψ", which outputs an explicit token, also subject to a loss. All components ("LLM Layer i", "Scorer", "CCoT φ", "Decoder ψ") are trainable.
**2.2 SoftCoT Model:**
* **Components:**
* "Assistant LLM": A horizontally elongated rectangle on the bottom-left, with a snowflake icon indicating it is **Frozen**.
* "Linear Layer": A horizontally elongated rectangle in the bottom-center, with a flame icon indicating it is **Trainable**.
* "Large Language Model" (LLM): A large, horizontally elongated oval-shaped box on the right, with a snowflake icon indicating it is **Frozen**.
* **Input Flow (Assistant LLM):**
* Two **Prompts** (grey rectangles) are fed into the bottom-left of the "Assistant LLM".
* **Output Flow (Assistant LLM):**
* Two **Continuous Tokens** (blue rectangles) are output from the top of the "Assistant LLM".
* **Input Flow (Linear Layer):**
* The two **Continuous Tokens** (blue rectangles) from the "Assistant LLM" are fed into the bottom-left of the "Linear Layer".
* **Output Flow (Linear Layer):**
* Two **Continuous Tokens** (blue rectangles) are output from the top of the "Linear Layer".
* **Input Flow (Large Language Model):**
* Two **Prompts** (grey rectangles) are fed into the bottom-left of the LLM.
* The two **Continuous Tokens** (blue rectangles) from the "Linear Layer" are fed into the bottom-center of the LLM. A dashed blue arrow connects the output of the "Linear Layer" to these input continuous tokens.
* Three **Explicit Tokens** (green rectangles) are fed into the bottom-right of the LLM.
* **Output Flow (Large Language Model):**
* Two **Continuous Tokens** (blue rectangles) are output from the top-left of the LLM.
* Three **Explicit Tokens** (green rectangles) are output from the top-right of the LLM.
* **Loss Calculation:** A **Loss** (pink dashed rectangle with angle brackets) surrounds the three output **Explicit Tokens** and the three input **Explicit Tokens** to the LLM, indicating that the loss is calculated based on these explicit tokens.
* **Summary:** The SoftCoT model utilizes a frozen "Assistant LLM" to generate continuous tokens from prompts. These continuous tokens are then transformed by a trainable "Linear Layer". The resulting continuous tokens, along with additional prompts and explicit tokens, are fed into a frozen "Large Language Model". The LLM outputs continuous and explicit tokens, with a loss calculated based on the explicit tokens.
DECODING INTELLIGENCE...