TECHNICAL ASSET FINGERPRINT
b7867eda8c7c7476a58b31b7
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
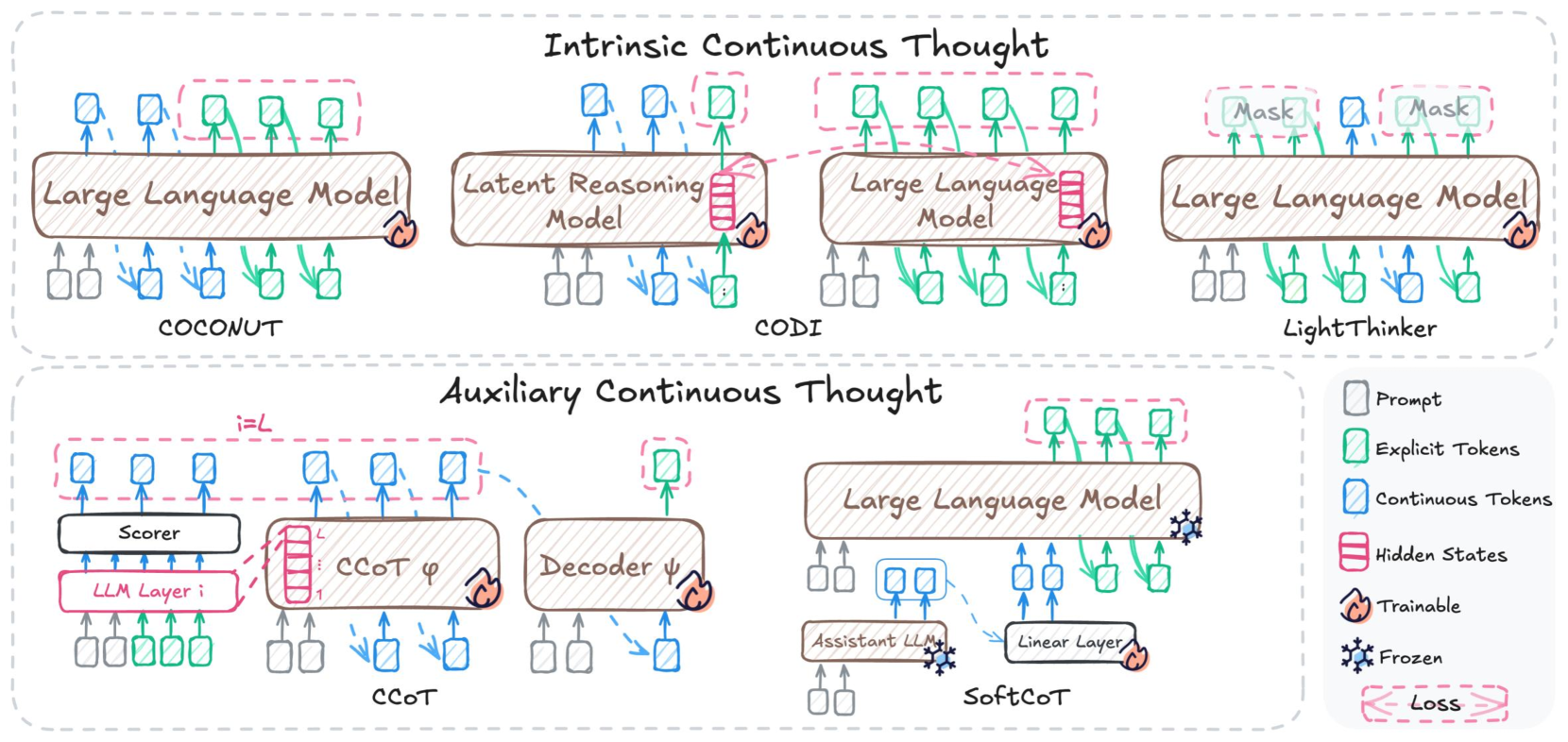
## Technical Architecture Diagram: LLM Continuous Thought Approaches
### Overview
The image is a technical diagram illustrating two categories of "Continuous Thought" processing in Large Language Models (LLMs): **Intrinsic Continuous Thought** (top section) and **Auxiliary Continuous Thought** (bottom section). It compares six distinct architectural approaches (COCONUT, CODI, an unnamed LLM variant, LightThinker, CCoT, SoftCoT) with labeled components, color-coded token types, and trainable/frozen status indicators. The diagram uses dashed boxes for hidden states/loss and icons (flame = trainable, snowflake = frozen) to distinguish design choices.
### Components/Axes
Since this is a diagram (not a chart), components are organized by section and sub-diagram:
- **Top Section (Intrinsic Continuous Thought)**: Four left-to-right sub-diagrams:
1. COCONUT: "Large Language Model" (brown box) with input/output tokens.
2. CODI: "Latent Reasoning Model" (brown box) with input/output tokens and "Hidden States" (pink dashed box).
3. Unnamed LLM Variant: "Large Language Model" (brown box) with input/output tokens and "Hidden States" (pink dashed box).
4. LightThinker: "Large Language Model" (brown box) with input/output tokens and "Mask" (pink dashed boxes) on output tokens.
- **Bottom Section (Auxiliary Continuous Thought)**: Two left-to-right sub-diagrams:
1. CCoT: "LLM Layer i" (pink box, labeled "i=L"), "Scorer" (white box), "CCoT φ" (brown box), "Decoder ψ" (brown box) with input/output tokens and "Loss" (pink dashed box).
2. SoftCoT: "Large Language Model" (brown box, frozen), "Assistant LLM" (brown box, frozen), "Linear Layer" (white box, trainable) with input/output tokens.
- **Legend (Bottom-Right)**: Color-coded tokens and status icons:
- Gray square: Prompt
- Green square: Explicit Tokens
- Blue square: Continuous Tokens
- Pink dashed box: Hidden States
- Flame icon: Trainable
- Snowflake icon: Frozen
- Pink dashed box with "Loss": Loss
### Detailed Analysis
#### Intrinsic Continuous Thought (Top Section)
1. **COCONUT**:
- Input: Gray (Prompt), blue (Continuous Tokens), green (Explicit Tokens) tokens.
- Model: "Large Language Model" (brown box, trainable: flame icon).
- Output: Blue (Continuous Tokens), green (Explicit Tokens) tokens.
- Flow: Input tokens feed directly into the trainable LLM, which generates continuous and explicit output tokens.
2. **CODI**:
- Input: Gray (Prompt), blue (Continuous Tokens), green (Explicit Tokens) tokens.
- Model: "Latent Reasoning Model" (brown box, trainable: flame icon) with "Hidden States" (pink dashed box) connected to the model.
- Output: Blue (Continuous Tokens), green (Explicit Tokens) tokens.
- Flow: Input tokens feed into the latent reasoning model, which uses hidden states to generate continuous and explicit output tokens.
3. **Unnamed LLM Variant**:
- Input: Gray (Prompt), blue (Continuous Tokens), green (Explicit Tokens) tokens.
- Model: "Large Language Model" (brown box, trainable: flame icon) with "Hidden States" (pink dashed box) connected to the model.
- Output: Blue (Continuous Tokens), green (Explicit Tokens) tokens.
- Flow: Input tokens feed into the LLM, which uses hidden states to generate continuous and explicit output tokens.
4. **LightThinker**:
- Input: Gray (Prompt), blue (Continuous Tokens), green (Explicit Tokens) tokens.
- Model: "Large Language Model" (brown box, trainable: flame icon).
- Output: Blue (Continuous Tokens), green (Explicit Tokens) tokens, with "Mask" (pink dashed boxes) applied to some output tokens.
- Flow: Input tokens feed into the LLM, which generates masked continuous and explicit output tokens.
#### Auxiliary Continuous Thought (Bottom Section)
1. **CCoT**:
- Input: Gray (Prompt), blue (Continuous Tokens), green (Explicit Tokens) tokens.
- Components: "LLM Layer i" (pink box, i=L), "Scorer" (white box, trainable: flame icon), "CCoT φ" (brown box, trainable: flame icon), "Decoder ψ" (brown box, trainable: flame icon).
- Output: Blue (Continuous Tokens), green (Explicit Tokens) tokens.
- Special: "Loss" (pink dashed box) connected to "LLM Layer i".
- Flow: Input tokens feed into "LLM Layer i", which connects to the Scorer, CCoT φ, and Decoder ψ (all trainable) to generate output tokens; loss is computed from LLM Layer i.
2. **SoftCoT**:
- Input: Gray (Prompt), blue (Continuous Tokens), green (Explicit Tokens) tokens.
- Components: "Large Language Model" (brown box, frozen: snowflake icon), "Assistant LLM" (brown box, frozen: snowflake icon), "Linear Layer" (white box, trainable: flame icon).
- Output: Blue (Continuous Tokens), green (Explicit Tokens) tokens.
- Flow: Input tokens feed into the frozen LLM and Assistant LLM, which connect to the trainable Linear Layer to generate output tokens.
### Key Observations
- **Categorization**: The diagram splits continuous thought approaches into **intrinsic** (integrated into the LLM) and **auxiliary** (separate external components).
- **Trainable vs Frozen**: Intrinsic approaches (COCONUT, CODI, LightThinker) and CCoT use fully trainable components; SoftCoT uses frozen LLMs with a trainable Linear Layer.
- **Special Elements**: Hidden states (CODI, unnamed LLM) imply latent reasoning; masks (LightThinker) suggest selective token processing; scorers/decoders (CCoT) indicate structured output generation; loss (CCoT) shows training signal integration.
- **Token Consistency**: All approaches use three token types (Prompt, Explicit, Continuous) as defined in the legend.
### Interpretation
This diagram clarifies tradeoffs in LLM continuous thought design:
- **Intrinsic Approaches**: Embed reasoning directly into the LLM, simplifying architecture but requiring full model training. Hidden states (CODI) enable latent reasoning, while masks (LightThinker) allow selective token processing for efficiency.
- **Auxiliary Approaches**: Use modular external components to augment LLMs. CCoT integrates training loss for structured output, while SoftCoT leverages pre-trained frozen LLMs with a trainable linear layer to reduce training costs.
- **Practical Impact**: Researchers can choose intrinsic methods for end-to-end reasoning or auxiliary methods for modular, efficient augmentation. The diagram highlights how each approach modifies token flow, model training, and reasoning logic to enhance LLM capabilities.
DECODING INTELLIGENCE...