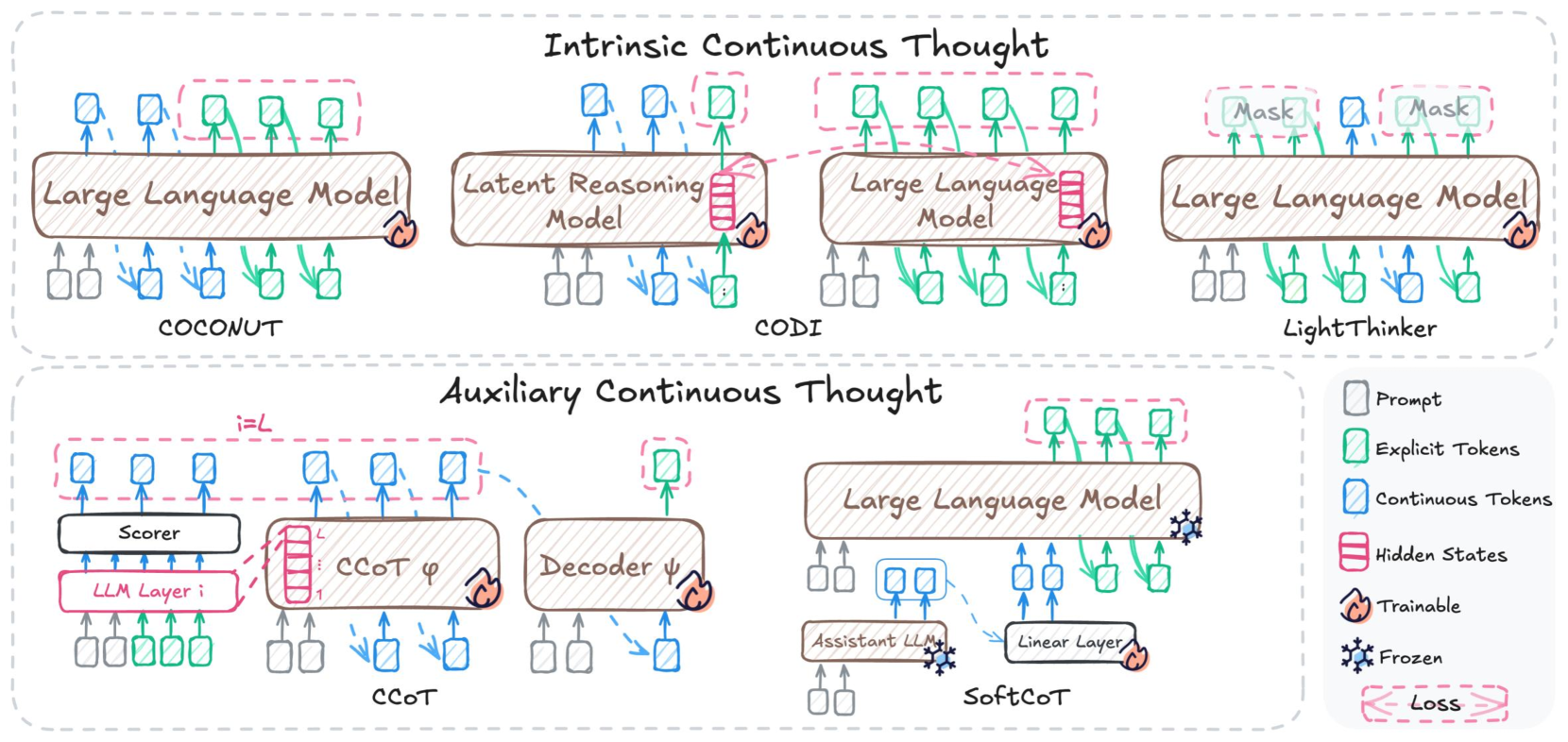
## Diagram: Continuous Thought Architectures in Large Language Models
### Overview
The diagram illustrates two primary paradigms for continuous thought processing in large language models (LLMs): **Intrinsic Continuous Thought** (top) and **Auxiliary Continuous Thought** (bottom). It uses color-coded symbols to represent different components (prompts, tokens, hidden states) and their interactions across model architectures like COCONUT, CODI, LightThinker, CCOT, and SoftCoT.
### Components/Axes
#### Legend (right side):
- **Gray squares**: Prompts
- **Green squares**: Explicit Tokens
- **Blue squares**: Continuous Tokens
- **Red dashed rectangles**: Hidden States
- **Orange flame icon**: Trainable parameters
- **Blue snowflake icon**: Frozen parameters
- **Dashed red arrows**: Loss gradients
#### Key Architectural Elements:
1. **Intrinsic Continuous Thought** (top section):
- **COCONUT**:
- Large Language Model (LLM) with explicit/continuous token integration
- Direct interaction with latent reasoning modules
- **CODI**:
- Latent Reasoning Model with bidirectional LLM interactions
- Continuous token generation from hidden states
- **LightThinker**:
- LLM with masked token prediction
- Continuous token refinement through iterative masking
2. **Auxiliary Continuous Thought** (bottom section):
- **CCOT**:
- Scorer module evaluating LLM layer outputs
- Continuous token generation via decoder ψ
- **SoftCoT**:
- Assistant LLM guiding linear layer operations
- Continuous token refinement through auxiliary reasoning
### Detailed Analysis
#### Intrinsic Continuous Thought Flow:
1. **COCONUT**:
- Prompts (gray) → LLM processes explicit tokens (green) and continuous tokens (blue)
- Hidden states (red) feed into latent reasoning modules
- Continuous tokens emerge from LLM's middle layers (layer i)
2. **CODI**:
- Latent reasoning modules process LLM hidden states
- Continuous tokens generated through iterative reasoning
- Final output combines explicit and continuous tokens
3. **LightThinker**:
- Masked token prediction (red dashed boxes) guides continuous token generation
- Continuous tokens refine LLM outputs through iterative masking
#### Auxiliary Continuous Thought Flow:
1. **CCOT**:
- Scorer evaluates LLM layer outputs (i=1 to L)
- Continuous tokens generated via decoder ψ
- Loss gradients (dashed red) backpropagate through LLM layers
2. **SoftCoT**:
- Assistant LLM (frozen) guides linear layer operations
- Continuous tokens refined through auxiliary reasoning
- Trainable parameters (orange) in linear layer and decoder
### Key Observations
1. **Token Dynamics**:
- Explicit tokens (green) remain static across layers
- Continuous tokens (blue) evolve through model processing
- Hidden states (red) serve as intermediate representations
2. **Trainability**:
- Most components are frozen (blue snowflake)
- Exceptions: CCOT decoder ψ, SoftCoT linear layer, and LLM layers in CCOT
3. **Loss Propagation**:
- Loss gradients primarily affect LLM layers in CCOT
- LightThinker shows distributed loss across masking operations
### Interpretation
This diagram reveals a critical distinction between intrinsic and auxiliary continuous thought approaches:
- **Intrinsic models** (COCONUT, CODI, LightThinker) embed continuous reasoning directly within LLM processing, using hidden states and iterative masking
- **Auxiliary models** (CCOT, SoftCoT) treat continuous thought as a separate module, using scorers and decoders to refine outputs
The architecture suggests that continuous token generation requires either:
1. Deep integration with LLM hidden states (intrinsic), or
2. Explicit auxiliary modules that evaluate and refine outputs (auxiliary)
Notably, the use of frozen parameters in most components implies that continuous thought capabilities are primarily learned through specialized modules rather than full LLM retraining. The presence of loss gradients in CCOT but not in intrinsic models indicates different training paradigms for continuous reasoning development.