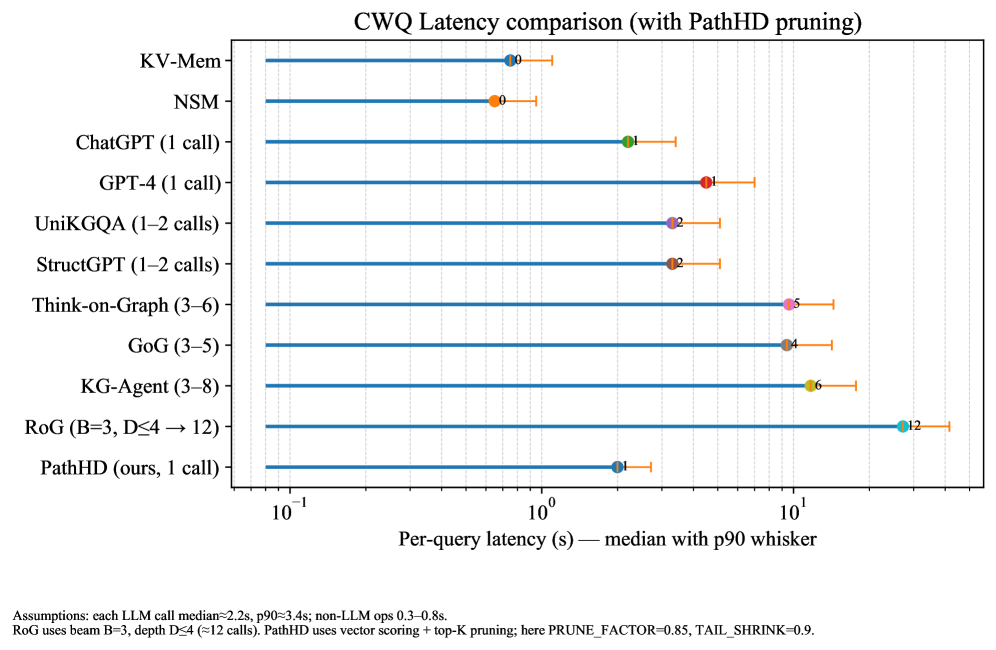
## Horizontal Bar Chart: CWQ Latency Comparison (with PathHD Pruning)
### Overview
This image is a horizontal bar chart comparing the per-query latency (in seconds) of various question-answering or reasoning systems on the CWQ (Complex WebQuestions) benchmark. The chart specifically evaluates performance when using "PathHD pruning." The latency is presented on a logarithmic scale, showing the median value (as a colored dot) and the 90th percentile (p90) value (as an orange whisker extending to the right).
### Components/Axes
* **Chart Title:** "CWQ Latency comparison (with PathHD pruning)"
* **Y-Axis (Vertical):** Lists the names of the systems/methods being compared. From top to bottom:
1. KV-Mem
2. NSM
3. ChatGPT (1 call)
4. GPT-4 (1 call)
5. UniKGQA (1–2 calls)
6. StructGPT (1–2 calls)
7. Think-on-Graph (3–6)
8. GoG (3–5)
9. KG-Agent (3–8)
10. RoG (B=3, D≤4 → 12)
11. PathHD (ours, 1 call)
* **X-Axis (Horizontal):** Labeled "Per-query latency (s) — median with p90 whisker". It uses a logarithmic scale with major tick marks at `10^-1` (0.1), `10^0` (1), and `10^1` (10) seconds.
* **Data Representation:** Each system has a horizontal blue bar. A colored dot on the bar marks the median latency. An orange horizontal line (whisker) extending to the right from the dot marks the p90 latency. The numerical value of the median latency (in seconds) is printed next to each dot.
* **Assumptions & Notes (Bottom of Image):**
* "Assumptions: each LLM call median=2.2s, p90=3.4s; non-LLM ops 0.3–0.8s."
* "RoG uses beam B=3, depth D≤4 (=12 calls). PathHD uses vector scoring + top-K pruning; here PRUNE_FACTOR=0.85, TAIL_SHRINK=0.9."
### Detailed Analysis
The chart presents the following latency data (median, with approximate p90 indicated by whisker length):
1. **KV-Mem:** Median ≈ 0.9s. The p90 whisker extends to approximately 1.2s.
2. **NSM:** Median ≈ 1.0s. The p90 whisker extends to approximately 1.3s.
3. **ChatGPT (1 call):** Median ≈ 2.1s. The p90 whisker extends to approximately 3.4s.
4. **GPT-4 (1 call):** Median ≈ 4.1s. The p90 whisker extends to approximately 6.5s.
5. **UniKGQA (1–2 calls):** Median ≈ 3.2s. The p90 whisker extends to approximately 5.0s.
6. **StructGPT (1–2 calls):** Median ≈ 3.2s. The p90 whisker extends to approximately 5.0s.
7. **Think-on-Graph (3–6):** Median ≈ 9.5s. The p90 whisker extends to approximately 15s.
8. **GoG (3–5):** Median ≈ 9.4s. The p90 whisker extends to approximately 15s.
9. **KG-Agent (3–8):** Median ≈ 10.6s. The p90 whisker extends to approximately 18s.
10. **RoG (B=3, D≤4 → 12):** Median ≈ 12s. The p90 whisker extends to approximately 20s.
11. **PathHD (ours, 1 call):** Median ≈ 2.0s. The p90 whisker extends to approximately 3.0s.
**Trend Verification:** The visual trend shows a general increase in latency as we move down the list from KV-Mem/NSM to RoG, with PathHD being a notable exception near the bottom. Systems requiring more LLM calls (indicated in parentheses, e.g., 3-6, 3-8, 12) consistently show higher median latencies (9.4s - 12s) compared to systems with 1-2 calls (2.1s - 4.1s).
### Key Observations
* **Lowest Latency:** The non-LLM methods, **KV-Mem** (0.9s) and **NSM** (1.0s), have the lowest median latencies.
* **Highest Latency:** **RoG** has the highest median latency at approximately 12 seconds, which aligns with its note of using up to 12 LLM calls.
* **PathHD Performance:** The proposed method, **PathHD (ours, 1 call)**, achieves a median latency of ~2.0s, which is competitive with the single-call LLM baselines (ChatGPT at 2.1s) and significantly faster than multi-call reasoning systems.
* **LLM Call Impact:** There is a clear correlation between the number of LLM calls (noted in parentheses) and increased latency. Systems with 3+ calls all have medians above 9 seconds.
* **Variability (p90):** The p90 whiskers show that latency variability is generally proportional to the median latency. RoG and KG-Agent show the largest absolute spread between median and p90.
### Interpretation
This chart is a performance benchmark designed to demonstrate the efficiency of the "PathHD" method. The key takeaway is that **PathHD achieves low latency (comparable to a single call to ChatGPT) while presumably maintaining the reasoning capabilities of more complex, multi-step systems.**
The data suggests a fundamental trade-off in these systems: methods that perform extensive reasoning or graph traversal (like RoG, KG-Agent, Think-on-Graph) incur a significant latency cost, often an order of magnitude higher than simpler retrieval or single-inference methods. PathHD appears to be positioned as a solution that breaks this trade-off, offering the speed of a single LLM call.
The assumptions at the bottom are critical for interpretation. They provide a baseline cost for LLM operations (2.2s median), against which the total system latencies can be judged. For example, ChatGPT's 2.1s median is very close to the assumed single-call cost, while GPT-4's 4.1s suggests additional overhead. PathHD's 2.0s median, being slightly below the single LLM call assumption, implies its "vector scoring + top-K pruning" mechanism adds negligible overhead, making it a highly efficient pruning strategy for the CWQ task. The chart effectively argues for PathHD's practical advantage in real-time or high-throughput applications where query latency is a critical constraint.